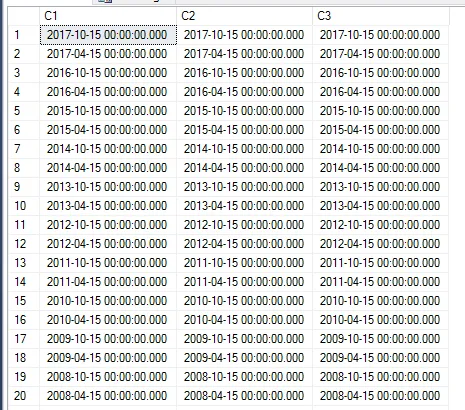
我有一个在SQL服务器中的表格,其中包含一些日期。现在我想创建一个查询语句,使其返回一个列包含所有日期,第二个列包含第一个列的前一个日期,第三个列包含第二列的前一个日期(c2)。 例如:
c1(orginal) c2(prevoius of c1) c3(previous of c2)
2017-10-15 00:00:00 2017-04-15 00:00:00 2016-10-15 00:00:00
2017-04-15 00:00:00 2016-10-15 00:00:00 2016-04-15 00:00:00
2016-10-15 00:00:00 2016-04-15 00:00:00 2015-10-15 00:00:00
2016-04-15 00:00:00 2015-10-15 00:00:00 null
2015-10-15 00:00:00 null null
颜色示例:
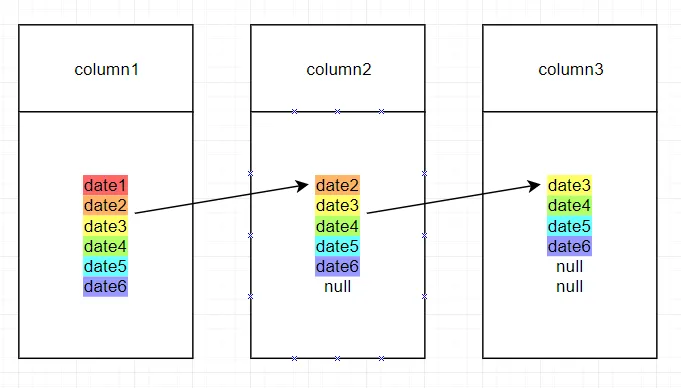
是否可以创建一个 SELECT 语句,其中第一行将是列1中的第一个日期,第二行将是列1中的第二个日期,以此类推。第二行将是列1中的第二个日期,第三行将是列1中的第三个日期,以此类推。
我的当前查询:
SELECT DISTINCT(BFSSTudStichdatum) AS C1, BFSSTudStichdatum AS C2,
BFSSTudStichdatum AS C3 FROM BFSStudierende
ORDER BY C1 DESC
结果: