我正在尝试逆向工程一种二进制文件格式,但它没有魔法字节和具体扩展名。我只能影响文件的一个方面:一个短字符串。通过尝试不同的字符串,我能够找出文件中数据是如何存储的。整个文件似乎使用某种简单的编码。我希望找到确切的编码方式可以缩小我的文件格式搜索范围。我知道该文件是由一个用C++编写的Windows程序生成的。
现在,在经过多次尝试之后,我发现文件的某些部分使用run进行编码。每个run都以一个指示将要跟随多少个字节以及从哪里检索数据的字节开头。
你知道这种编码吗?或者你有什么提示可以让我在文件中查找以识别编码?
现在,在经过多次尝试之后,我发现文件的某些部分使用run进行编码。每个run都以一个指示将要跟随多少个字节以及从哪里检索数据的字节开头。
000ddddd(1字节)
从编码数据中取出接下来的(ddddd)+1个字节。111····· ···ddddd ···bbbbb(3字节)
回到已解密数据中(bbbbb)+1个字节,并从其后继续取出(ddddd)+9个字节。ddd····· ··bbbbbb(2字节)
回到已解密数据中(bbbbbb)+1个字节,并从其后继续取出(ddd)+2个字节。
然而,我不知道这可能是什么编码/压缩算法。它看起来像一些不使用字典的LZ变体(如LZ77),但到目前为止,我还没有找到任何与此描述相匹配的算法。我也不确定整个文件是否都是这样编码的,还是只有部分内容。This is the start of the file, with the UTF-16 string
abracadabraencoded in it:
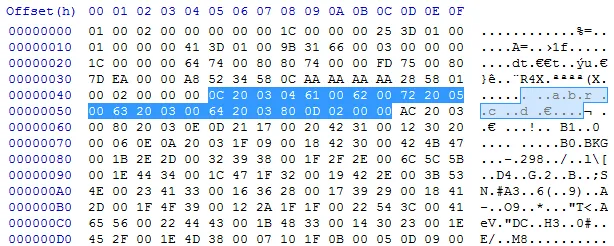
. . . a . b . r . . c . . d . € . 0C 20 03 04 61 00 62 00 72 20 05 00 63 20 03 00 64 20 03 80 0DTo decode the string:
0C number of Unicode chars: 12 (11 chars + \0) 20 03 . . . ?? 04 next 5 61 00 a . 62 00 b . 72 r 20 05 . a . back 6, take 3 00 next 1 63 c 20 03 . a . back 4, take 3 00 next 1 64 d 20 03 . a . back 4, take 3 80 0D b . r . a . back 14, take 6This results in (UTF-16):
a . b . r . a . c . a . d . a . b . r . a . 61 00 62 00 72 00 61 00 63 00 61 00 64 00 61 00 62 00 72 00 61 00
你知道这种编码吗?或者你有什么提示可以让我在文件中查找以识别编码?