我正在使用LibSVM对一些文档进行分类。最终的结果显示,这些文档似乎有些难以分类。然而,在训练模型时我注意到了一些事情。就是:假设我的训练集有1000个,其中大约有800个被选为支持向量。
我已经到处寻找是否这是一件好事或坏事。我的意思是,支持向量的数量与分类器的性能之间是否存在关系?
我已阅读过这篇先前的帖子,但是我正在执行参数选择,并且我确定特征向量中的属性都是有序的。
我只需要知道它们之间的关系。
谢谢。
p.s:我使用线性内核。
我正在使用LibSVM对一些文档进行分类。最终的结果显示,这些文档似乎有些难以分类。然而,在训练模型时我注意到了一些事情。就是:假设我的训练集有1000个,其中大约有800个被选为支持向量。
我已经到处寻找是否这是一件好事或坏事。我的意思是,支持向量的数量与分类器的性能之间是否存在关系?
我已阅读过这篇先前的帖子,但是我正在执行参数选择,并且我确定特征向量中的属性都是有序的。
我只需要知道它们之间的关系。
谢谢。
p.s:我使用线性内核。
支持向量机是一个优化问题。它们试图找到将两个类分开的超平面,并且具有最大间隔的支持向量是落在此间隔内的点。如果您从简单到更复杂地构建它,那么理解起来会很容易。
硬间隔线性SVM
在训练集中,数据是线性可分的,并且使用硬间隔(不允许有松弛),支持向量是落在支撑超平面上的点(这些超平面与边缘处分界超平面平行)。
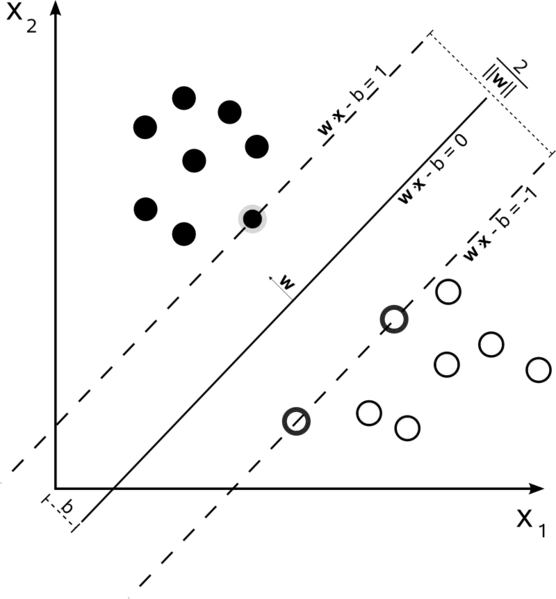
所有支持向量都恰好位于边缘上。无论数据集的维度或大小是多少,支持向量的数量可能只有2个。
软间隔线性SVM
但是,如果我们的数据集不是线性可分的呢?我们引入了软间隔SVM。我们不再要求数据点位于边缘之外,而是允许一些数据点偏离超平面进入边缘。我们使用松弛参数C(nu-SVM中的nu)来控制这一点。这样可以给我们更宽的边缘和更大的训练数据误差,但有助于泛化或允许我们找到非线性可分离数据的线性分割。
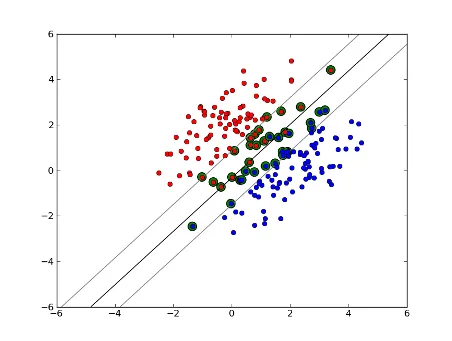
现在,支持向量的数量取决于我们允许多少松弛以及数据的分布情况。如果我们允许大量松弛,那么我们将有大量的支持向量。如果我们几乎不允许松弛,则支持向量的数量很少。准确性取决于找到适合分析数据的松弛水平。对于某些数据,可能无法获得高精度,我们必须尽力找到最佳拟合。
非线性SVM
这将我们带到了非线性SVM。我们仍然试图在线性空间中划分数据,但现在我们尝试在更高维的空间中进行。这是通过核函数完成的,当然它有自己的一套参数。当我们将其转换回原始特征空间时,结果就是非线性的: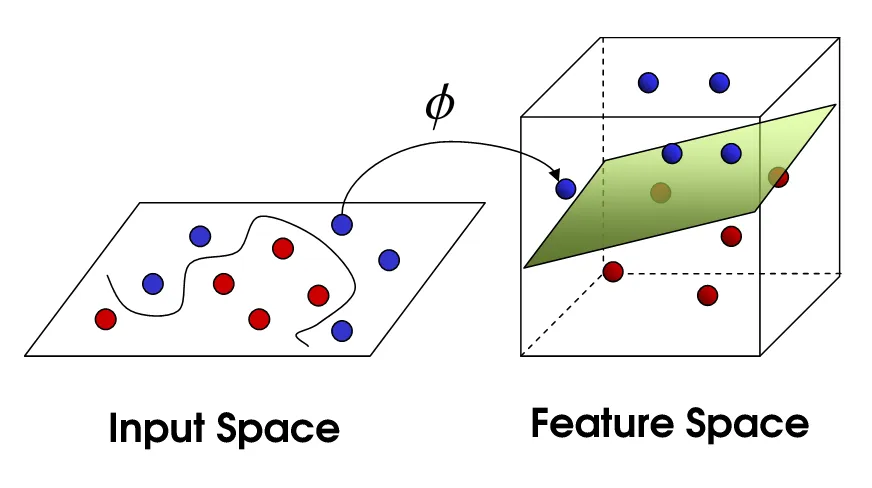
800个样本中的大部分,基本上告诉你SVM需要使用几乎每个训练样本来编码训练集。这基本上告诉您,您的数据没有太多的规律性。
听起来你的主要问题是缺乏足够的训练数据。此外,也许考虑一些特定的特征来更好地区分这些数据。
样本数量和属性数量都可能影响支持向量的数量,使得模型更加复杂。我相信您使用单词甚至ngrams作为属性,因此它们的数量很多,并且自然语言模型本身非常复杂。因此,在1000个样本中有800个支持向量似乎是可以接受的。(还要注意@karenu关于C/nu参数的评论,这些参数也对SVs数量有很大影响)。
要理解这一点,请回想SVM的主要思想。SVM在一个多维特征空间中工作,并试图找到分隔所有给定样本的超平面。如果你有很多样本,但只有2个特征(2维),数据和超平面可能如下所示:
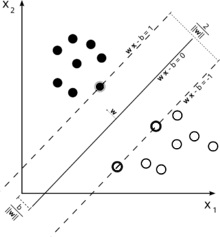
这里只有3个支持向量,其他所有支持向量都在它们后面,因此不起任何作用。请注意,这些支持向量仅由2个坐标定义。
现在想象一下,你有一个三维空间,因此支持向量由3个坐标定义。
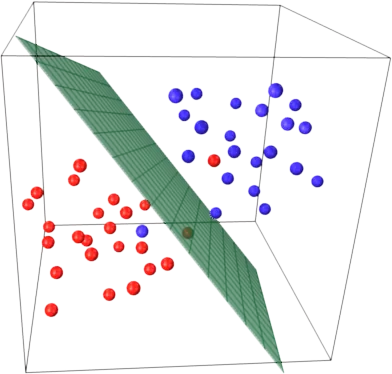
这意味着有一个参数(坐标)需要调整,这可能需要更多的样本来找到最优的超平面。换句话说,在最坏的情况下,SVM每个样本只找到一个超平面坐标。
当数据结构良好(即相当好地保持了模式)时,可能只需要几个支持向量-其他所有支持向量都会留在它们后面。但文本是非常不良结构化的数据。SVM尽最大努力尝试尽可能合适地拟合样本,因此甚至要将更多的样本作为支持向量。随着样本数量的增加,这种“异常”会减少(更多的不重要的样本出现),但支持向量的绝对数量仍然很高。
SVM分类与支持向量(SVs)的数量成正比。支持向量的数量在最坏情况下等于训练样本数,因此800/1000尚未达到最坏情况,但它仍然很糟糕。
然而,1000个训练文档是一个相对较小的训练集。您应该检查当您扩大到10000个或更多文档时会发生什么。如果情况没有改善,请考虑使用线性SVM,通过LibLinear进行训练,用于文档分类;这些能够更好地扩展(模型大小和分类时间与特征数量成正比且独立于训练样本数量)。
来源之间存在一些混淆。例如,在教科书ISLR 6th Ed中,C被描述为“边界违规预算”,因此高C会导致更多的边界违规和支持向量。 但是在R和Python的SVM实现中,参数C被实现为“违反惩罚”,这是相反的,然后您会观察到在C值较高时支持向量较少。