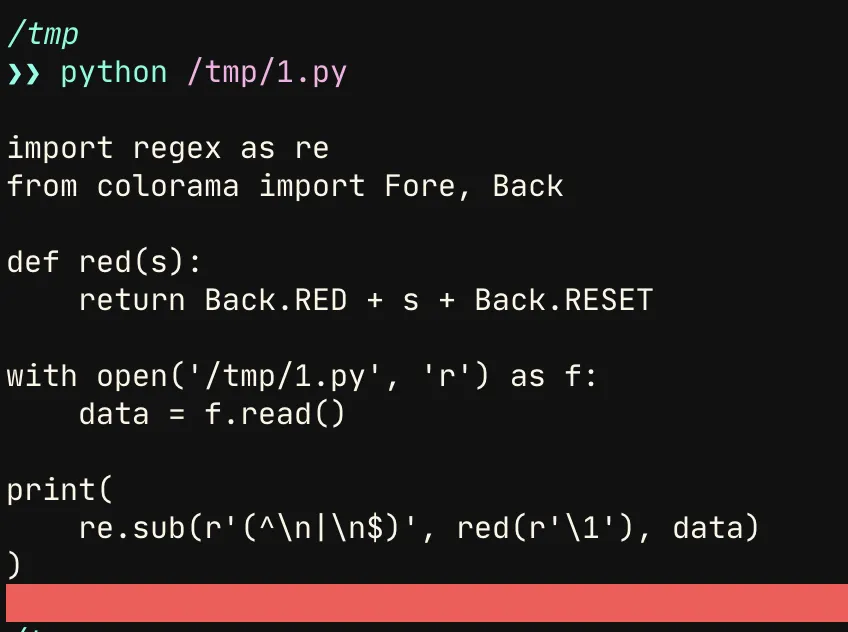
我正在尝试编写一个简单的正则表达式,只有当换行符出现在数据的开头或结尾时才会突出显示它们,并保留换行符。在下面的示例中,第1行和第14行都是换行符。这两行是我想要突出显示的,因为它们出现在数据的开头和结尾。
在这个公式中,数据与上面发布的示例内容相同。
在上面的例子中,这是我得到的结果:
import regex as re
from colorama import Fore, Back
def red(s):
return Back.RED + s + Back.RESET
with open('/tmp/1.py', 'r') as f:
data = f.read()
print(
re.sub(r'(^\n|\n$)', red(r'\1'), data)
)
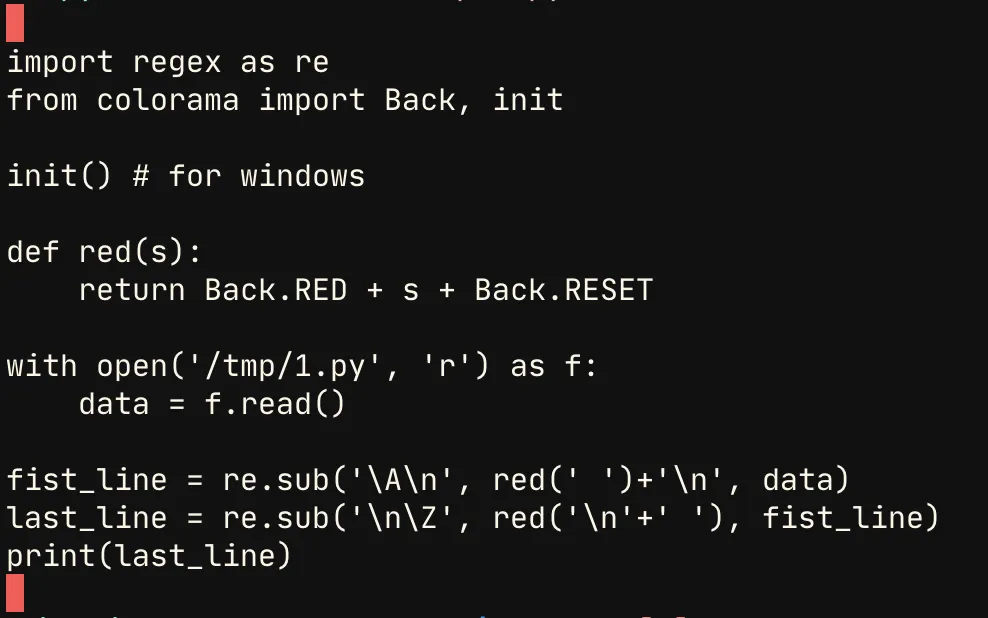
在这个公式中,数据与上面发布的示例内容相同。
在上面的例子中,这是我得到的结果:
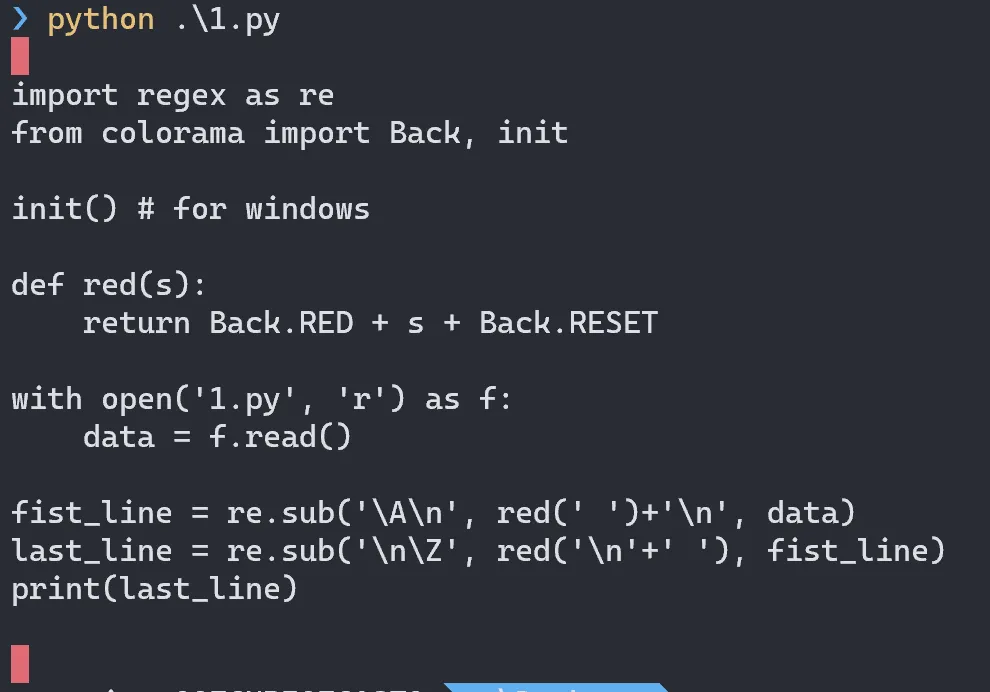
^和$匹配行的开头/结尾,而不是整个内容的开头/结尾。 - Benoît Zu(^\n|\n$)还是(\A\n|\n\Z),我都会在开头和结尾看到"\x1b[41m\n\x1b[49"。所以我无法复制您的问题。在我的Windows 10平台上,两者都不会产生红线,但这是一个不同的问题。当我在Linux上运行它时,直到输出位于屏幕底部,我仍然看不到红色,然后第一条红线神秘地出现在import语句之后。也许创建围绕换行符的红线的方法有问题。 - Booboored(r'\1')只会在第一次匹配时被评估一次,无论\1是什么值,都将用于后续替换。它在你的情况下起作用,因为在你的情况下每个匹配都是相同的,即\n,因此你可以使用相同的替换。但一般来说,这是错误的做法。更好的方法是:lambda m: red(m[1]),以确保red被调用每个匹配。 - Booboo