这被称为多任务学习,基本上意味着一个模型学习多个函数,但共享(部分或全部)权重。例如,用于图像识别和检测的一个模型。您需要做的是定义几个损失函数(它们被称为头部)。
下面是一个在tensorflow中学习Y1和Y2从X中的非常简单的示例(来自此文章系列):
# Define the Placeholders
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 1], name="Y1")
Y2 = tf.placeholder("float", [10, 1], name="Y2")
# Define the weights for the layers
shared_layer_weights = tf.Variable([10,20], name="share_W")
Y1_layer_weights = tf.Variable([20,1], name="share_Y1")
Y2_layer_weights = tf.Variable([20,1], name="share_Y2")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer_weights = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1,Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2,Y2_layer)
如果您希望使用纯scikit进行编码,请参阅sklearn.multiclass包,它们支持多输出分类和多输出回归。下面是一个多输出回归的示例:
>>> from sklearn.datasets import make_regression
>>> from sklearn.multioutput import MultiOutputRegressor
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1)
>>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X)
array([[-154.75474165, -147.03498585, -50.03812219],
[ 7.12165031, 5.12914884, -81.46081961],
[-187.8948621 , -100.44373091, 13.88978285],
[-141.62745778, 95.02891072, -191.48204257],
[ 97.03260883, 165.34867495, 139.52003279],
[ 123.92529176, 21.25719016, -7.84253 ],
[-122.25193977, -85.16443186, -107.12274212],
[ -30.170388 , -94.80956739, 12.16979946],
[ 140.72667194, 176.50941682, -17.50447799],
[ 149.37967282, -81.15699552, -5.72850319]])
[更新]
以下是一份完整的多目标分类代码,请尝试运行它:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.multioutput import MultiOutputClassifier
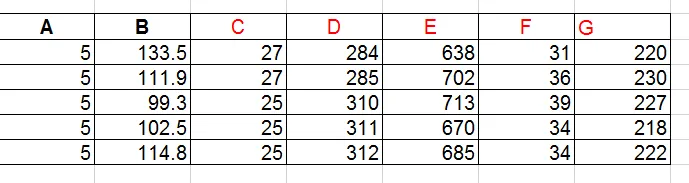
train_data = np.array([
[5, 133.5, 27, 284, 638, 31, 220],
[5, 111.9, 27, 285, 702, 36, 230],
[5, 99.3, 25, 310, 713, 39, 227],
[5, 102.5, 25, 311, 670, 34, 218],
[5, 114.8, 25, 312, 685, 34, 222],
])
test_data_x = np.array([
[5, 100.0],
[5, 105.2],
[5, 102.7],
[5, 103.5],
[5, 120.3],
[5, 132.5],
[5, 152.5],
])
x = train_data[:, :2]
y = train_data[:, 2:]
forest = RandomForestClassifier(n_estimators=100, random_state=1)
classifier = MultiOutputClassifier(forest, n_jobs=-1)
classifier.fit(x, y)
print classifier.predict(test_data_x)
输出(嗯,我觉得看起来很合理):
[[ 25. 310. 713. 39. 227.]
[ 25. 311. 670. 34. 218.]
[ 25. 311. 670. 34. 218.]
[ 25. 311. 670. 34. 218.]
[ 25. 312. 685. 34. 222.]
[ 27. 284. 638. 31. 220.]
[ 27. 284. 638. 31. 220.]]
如果因为某些原因这无法工作或在您的情况下无法应用,请更新问题。
{kind=link}
sklearn.model_selection.train_test_split。另外,您没有提供任何有关数据的详细信息,因此无法确定如何准备数据。 - Maxim