我正在使用Spark应用程序和Mongos控制台运行相同的聚合管道。在控制台上,数据可以在眨眼之间获取,并且只需要使用“it”一次即可检索所有预期数据。
但是,根据Spark WebUI显示,Spark应用程序需要近两分钟的时间。
我在Mongos控制台上运行的查询:
之后,我使用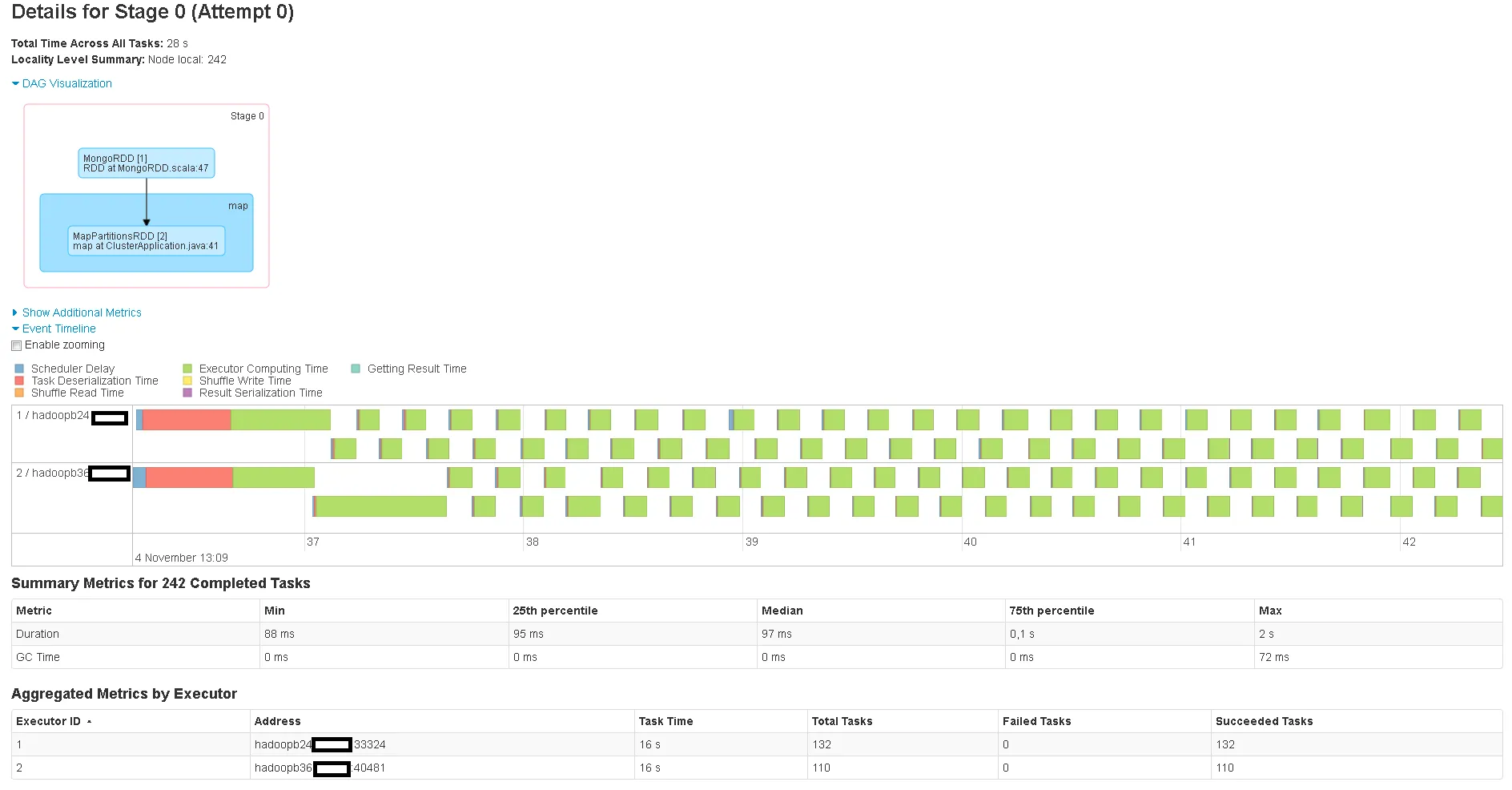

我在Mongos控制台上运行的查询:
db.data.aggregate([
{
$match:{
signals:{
$elemMatch:{
signal:"SomeSignal",
value:{
$gt:0,
$lte:100
}
}
}
}
},
{
$group:{
_id:"$root_document",
firstTimestamp:{
$min:"$ts"
},
lastTimestamp:{
$max:"$ts"
},
count:{
$sum:1
}
}
}
])
Spark应用程序代码
JavaMongoRDD<Document> rdd = MongoSpark.load(sc);
JavaMongoRDD<Document> aggregatedRdd = rdd.withPipeline(Arrays.asList(
Document.parse(
"{ $match: { signals: { $elemMatch: { signal: \"SomeSignal\", value: { $gt: 0, $lte: 100 } } } } }"),
Document.parse(
"{ $group : { _id : \"$root_document\", firstTimestamp: { $min: \"$ts\"}, lastTimestamp: { $max: \"$ts\"} , count: { $sum: 1 } } }")));
JavaRDD<String> outputRdd = aggregatedRdd.map(new Function<Document, String>() {
@Override
public String call(Document arg0) throws Exception {
String output = String.format("%s;%s;%s;%s", arg0.get("_id").toString(),
arg0.get("firstTimestamp").toString(), arg0.get("lastTimestamp").toString(),
arg0.get("count").toString());
return output;
}
});
outputRdd.saveAsTextFile("/user/spark/output");
之后,我使用
hdfs dfs -getmerge /user/spark/output/ output.csv并比较结果。为什么聚合如此缓慢?难道调用withPipeline不是为了减少需要传输到Spark的数据量吗?它看起来没有执行Mongos控制台执行的相同聚合操作。在Mongos控制台上,它非常快。我正在使用Spark 1.6.1和mongo-spark-connector_2.10版本1.1.0。编辑:我还想知道的另一件事是,两个执行器被启动(因为我目前正在使用默认执行设置),但只有一个执行器在工作。为什么第二个执行器没有任何工作?
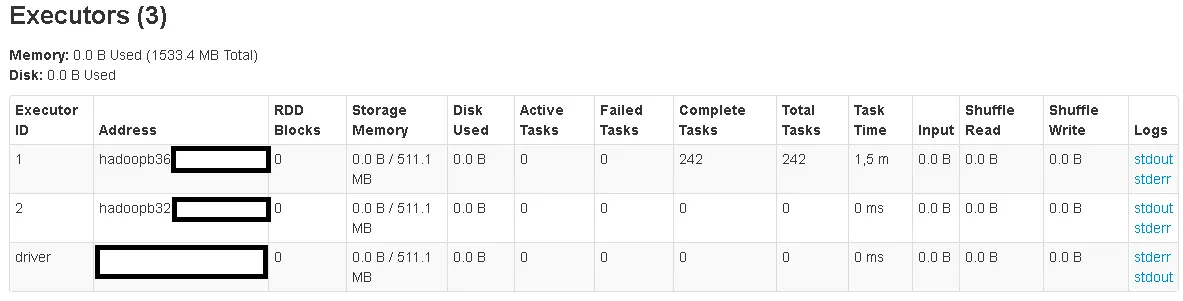
.count()而不是saveAsTextFile(..)时,也会创建242个任务。这次将返回65,000个文档。
aggregatedRdd上使用.count()而不是将其保存到 HDFS 时,也会创建242个任务。不同的查询返回几百万个文档。我的集合统计数据为:data : 15.01GiB docs : 45141000 chunks : 443。我怀疑把它写入 HDFS 不是问题所在。这只是在我的 Spark 应用程序中调用的唯一操作,这就是为什么它被列为 Web UI 中的唯一阶段。或者我错了吗? - j9dyDocument.parse("{ $match: {ts: {$gt: ISODate(\"2016-02-22T08:30:26.000Z\"), $lte: ISODate(\"2016-02-22T08:44:35.000Z\")} } }"),当我在rdd上调用.count()时,又创建了242个任务。你有什么想法吗?我已经在原帖中添加了另一张图片。 - j9dy