我不确定你的观察是否正确。我写了以下程序(在Linux上,希望你能将其移植到你的系统上)。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <errno.h>
#include <string.h>
#include <assert.h>
const unsigned possible_word_sizes[] = {
1, 2, 3, 4, 5,
8, 12, 16, 24,
32, 48, 64, 128,
256, 384, 2048
};
long long totalsize;
void **
malloc_chunks (int nbchunks)
{
const int nbsizes =
(int) (sizeof (possible_word_sizes)
/ sizeof (possible_word_sizes[0]));
void **ad = calloc (nbchunks, sizeof (void *));
if (!ad)
{
perror ("calloc chunks");
exit (EXIT_FAILURE);
};
for (int ix = 0; ix < nbchunks; ix++)
{
unsigned sizindex = random () % nbsizes;
unsigned size = possible_word_sizes[sizindex];
void *zon = malloc (size * sizeof (void *));
if (!zon)
{
fprintf (stderr,
"malloc#%d (%d words) failed (total %lld) %s\n",
ix, size, totalsize, strerror (errno));
exit (EXIT_FAILURE);
}
((int *) zon)[0] = ix;
totalsize += size;
ad[ix] = zon;
}
return ad;
}
void
free_chunks (void **chks, int nbchunks)
{
for (int i = 0; 3 * i < 2 * nbchunks; i++)
{
int pix = random () % nbchunks;
if (chks[pix])
{
free (chks[pix]);
chks[pix] = NULL;
}
}
for (int i = nbchunks - 1; i >= 0; i--)
if (chks[i])
{
free (chks[i]);
chks[i] = NULL;
}
}
int
main (int argc, char **argv)
{
assert (sizeof (int) <= sizeof (void *));
int nbchunks = (argc > 1) ? atoi (argv[1]) : 32768;
if (nbchunks < 128)
nbchunks = 128;
srandom (time (NULL));
printf ("nbchunks=%d\n", nbchunks);
void **chks = malloc_chunks (nbchunks);
clock_t clomall = clock ();
printf ("clomall=%ld totalsize=%lld words\n",
(long) clomall, totalsize);
free_chunks (chks, nbchunks);
clock_t clofree = clock ();
printf ("clofree=%ld\n", (long) clofree);
return 0;
}
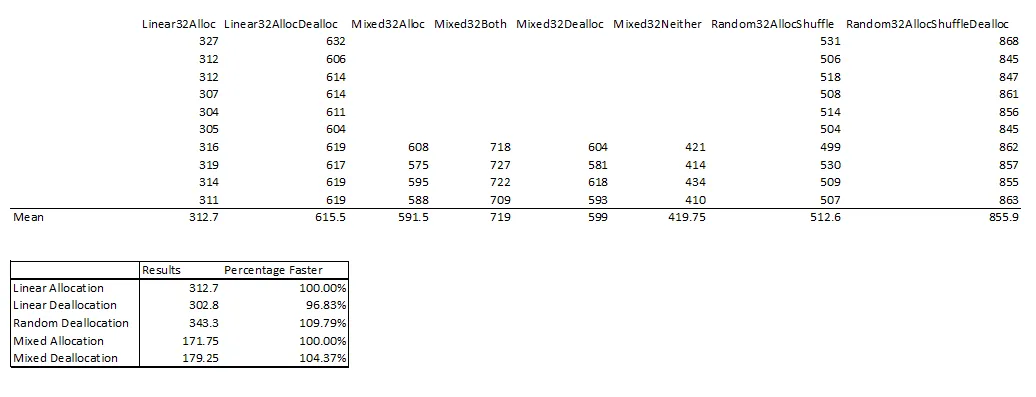
我在我的Debian/Sid/x86-64 (i3770k, 16Gb)上使用gcc -O2 -Wall mf.c -o mf进行编译。我运行time ./mf 100000,并获得以下结果:
nbchunks=100000
clomall=54162 totalsize=19115681 words
clofree=83895
./mf 100000 0.02s user 0.06s system 95% cpu 0.089 total
在我的系统上,
clock 返回 CPU 微秒。如果对
random 的调用可以忽略不计(我不确定是否可以),相对于
malloc 和
free 的时间,我倾向于不同意你的观察结果。
free 似乎比
malloc 快两倍。我的
gcc 版本是 6.1,我的
libc 版本是 Glibc 2.22。
请花些时间在您的系统上编译上述基准测试,并报告时间。
顺便说一句,我使用了Jerry的代码
g++ -O3 -march=native jerry.cc -o jerry
time ./jerry; time ./jerry; time ./jerry
提供
alloc time: 1940516
del time: 602203
./jerry 0.00s user 0.01s system 68% cpu 0.016 total
alloc time: 1893057
del time: 558399
./jerry 0.00s user 0.01s system 68% cpu 0.014 total
alloc time: 1818884
del time: 527618
./jerry 0.00s user 0.01s system 70% cpu 0.014 total
syscall()进行调用。所有在库中声明的分配/释放函数,例如C++的new/delete或C++的malloc,都可以扩展系统调用或直接调用它。这取决于操作系统的性能,因为您无法在其根本上重写分配的内核实现。 - Pierre Emmanuel Lallemantmalloc和new)和释放(free和delete)不是系统调用(在Linux上,列在syscalls(2)中...)。C运行时(例如malloc)有时可能会调用mmap或sbrk,但不总是(它尝试重用先前的free区域)。请参阅这里。 - Basile Starynkevitchmalloc分配许多随机大小的区域,并以某种随机顺序释放它们吗? - Basile Starynkevitch