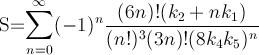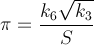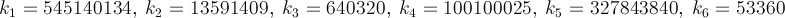我正在寻找最快的方法来获取π的值,这是一个个人挑战。更具体地说,我正在使用不涉及使用#define常量,如M_PI或硬编码数字的方式。
下面的程序测试了我所知道的各种方式。理论上,内联汇编版本是最快的选择,尽管显然不可移植。我将其包含在内作为与其他版本进行比较的基线。在我的测试中,使用内置函数,4 * atan(1)版本在GCC 4.2上最快,因为它自动折叠atan(1)成一个常数。指定-fno-builtin后,atan2(0,-1)版本最快。
以下是主要测试程序(pitimes.c):
下面的程序测试了我所知道的各种方式。理论上,内联汇编版本是最快的选择,尽管显然不可移植。我将其包含在内作为与其他版本进行比较的基线。在我的测试中,使用内置函数,4 * atan(1)版本在GCC 4.2上最快,因为它自动折叠atan(1)成一个常数。指定-fno-builtin后,atan2(0,-1)版本最快。
以下是主要测试程序(pitimes.c):
#include <math.h>
#include <stdio.h>
#include <time.h>
#define ITERS 10000000
#define TESTWITH(x) { \
diff = 0.0; \
time1 = clock(); \
for (i = 0; i < ITERS; ++i) \
diff += (x) - M_PI; \
time2 = clock(); \
printf("%s\t=> %e, time => %f\n", #x, diff, diffclock(time2, time1)); \
}
static inline double
diffclock(clock_t time1, clock_t time0)
{
return (double) (time1 - time0) / CLOCKS_PER_SEC;
}
int
main()
{
int i;
clock_t time1, time2;
double diff;
/* Warmup. The atan2 case catches GCC's atan folding (which would
* optimise the ``4 * atan(1) - M_PI'' to a no-op), if -fno-builtin
* is not used. */
TESTWITH(4 * atan(1))
TESTWITH(4 * atan2(1, 1))
#if defined(__GNUC__) && (defined(__i386__) || defined(__amd64__))
extern double fldpi();
TESTWITH(fldpi())
#endif
/* Actual tests start here. */
TESTWITH(atan2(0, -1))
TESTWITH(acos(-1))
TESTWITH(2 * asin(1))
TESTWITH(4 * atan2(1, 1))
TESTWITH(4 * atan(1))
return 0;
}
而内联汇编的东西(fldpi.c)只适用于x86和x64系统:
double
fldpi()
{
double pi;
asm("fldpi" : "=t" (pi));
return pi;
}
还有一个构建脚本,用于构建我正在测试的所有配置(build.sh):
#!/bin/sh
gcc -O3 -Wall -c -m32 -o fldpi-32.o fldpi.c
gcc -O3 -Wall -c -m64 -o fldpi-64.o fldpi.c
gcc -O3 -Wall -ffast-math -m32 -o pitimes1-32 pitimes.c fldpi-32.o
gcc -O3 -Wall -m32 -o pitimes2-32 pitimes.c fldpi-32.o -lm
gcc -O3 -Wall -fno-builtin -m32 -o pitimes3-32 pitimes.c fldpi-32.o -lm
gcc -O3 -Wall -ffast-math -m64 -o pitimes1-64 pitimes.c fldpi-64.o -lm
gcc -O3 -Wall -m64 -o pitimes2-64 pitimes.c fldpi-64.o -lm
gcc -O3 -Wall -fno-builtin -m64 -o pitimes3-64 pitimes.c fldpi-64.o -lm
除了在各种编译器标志之间进行测试(我也比较了32位和64位,因为优化不同),我还尝试过改变测试顺序。但是,每次都是atan2(0, -1)版本最优。