我运营一个网站,有约500个实时访问者、约50,000个每日访问者和约1.3百万总用户数。我在AWS上托管我的服务器,在那里我使用了几个不同种类的实例。当我开始运营网站时,不同实例的成本大致相同。当网站开始获得用户时,RDS实例(MySQL DB)的CPU经常达到峰值,我不得不多次升级它,现在它已经开始占据主要性能和月度成本的大部分(约95%的(2,8k$/month))。我目前使用一个具有16vCPU和64GiB RAM的数据库服务器,我还使用Multi-AZ Deployment来防止故障。我想知道数据库是否如此昂贵,或者我做错了什么?
如果您需要更多信息,请询问,非常感谢对此问题的任何帮助!
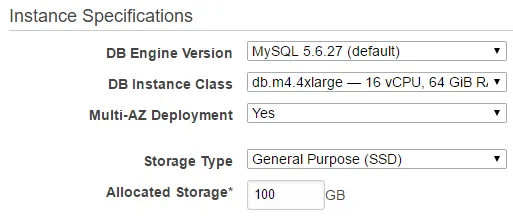

数据库信息
目前我的数据库有40个表,其中大部分表格拥有100k行数据,有些则有约200万行数据,而只有1个表格拥有3000万行数据。我有一个系统,用于归档那些不再需要的超过21天的旧数据行。
网站信息
网站主要使用PHP,但也使用了一些NodeJS和python。
网站的大部分功能工作方式如下:
- 开始事务
- 插入行
- 获取最后插入的ID(lastrowid)
- 进行某些计算
- 更新插入的行
- 更新用户
- 提交事务
我还运行了大约100个机器人,它们以10-30秒的间隔从数据库中轮询,并且有时也会插入/更新数据库。
其他
我已尝试多种方法来降低数据库的负载,例如启用数据库缓存、为某些查询使用redis缓存、尝试删除非常慢的查询、尝试升级存储类型为“配置型IOPS SSD”。但是没有任何改变似乎能够帮助解决问题。
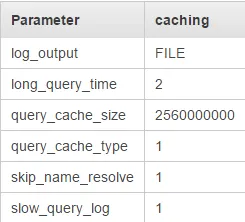
这是我对设置参数所做的更改:
如果您需要更多信息,请询问,非常感谢对此问题的任何帮助!