想知道使用Python从"blah blah blah test.this@gmail.com blah blah"中匹配"test.this"的最佳方法是什么?
我尝试了re.split(r"\b\w.\w@")
正则表达式中的 . 是一个元字符,它可以匹配任意字符。如果要在Python原始字符串(r"" 或者 r'')中匹配一个字面上的点,你需要转义它,因此使用 r"\."
\ (\\)。因此,这些表达式都是等价的:'\\.',"\\.",r'\.',r"\."。详情请参见:https://dev59.com/pFQK5IYBdhLWcg3wKc3k#52335971。 - Gabriel Staplesr"..." 语法是 Python 中的 "原始" 字符串,而不是 "常规" 字符串。 - GrandOpener'\\.',"\\.",而原始字符串需要单斜杠:r'\.',r"\.",这也是我评论的全部意图。这个答案没有表明清楚。我想在我的评论中澄清这一点,为了那些使用普通字符串的人,因为这个答案只适用于原始字符串。 - Gabriel Staplessplit。split 将在字符串周围拆分您的字符串。例如:>>> re.split(r"\b\w+\.\w+@", s)
['blah blah blah ', 'gmail.com blah blah']
re.findall 方法:>>> re.findall(r'\w+[.]\w+(?=@)', s) # look ahead
['test.this']
>>> re.findall(r'(\w+[.]\w+)@', s) # capture group
['test.this']
"默认情况下,点(.)匹配除换行符以外的任何字符。如果指定了DOTALL标志,则该模式将匹配包括换行符在内的任何字符。"(Python文档)
因此,如果您想要直接匹配点号,请将其放在方括号中:
>>> p = re.compile(r'\b(\w+[.]\w+)')
>>> resp = p.search("blah blah blah test.this@gmail.com blah blah")
>>> resp.group()
'test.this'
这是我对 @Yuushi 的主要回答的补充:
以下内容是不被允许的。
'\.' # NOT a valid escape sequence in **regular** Python single-quoted strings
"\." # NOT a valid escape sequence in **regular** Python double-quoted strings
他们会导致如下警告:
DeprecationWarning: 无效的转义序列
\.
然而,所有这些都是允许的且等价的:
# Use a DOUBLE BACK-SLASH in Python _regular_ strings
'\\.' # **regular** Python single-quoted string
"\\." # **regular** Python double-quoted string
# Use a SINGLE BACK-SLASH in Python _raw_ strings
r'\.' # Python single-quoted **raw** string
r"\." # Python double-quoted **raw** string
请记住,如果在正常字符串('some string'或"some string")中使用而不是原始字符串(r'some string'或r"some string"),则Python中的反斜杠(\)字符本身必须进行转义。因此,请注意您正在使用的字符串类型。为了在正常python字符串中转义正则表达式中的点或句号(.),因此,您还必须通过使用双反斜杠(\\)来转义反斜杠,从而使正则表达式中的.的总转义序列为:\\.,如上例所示。
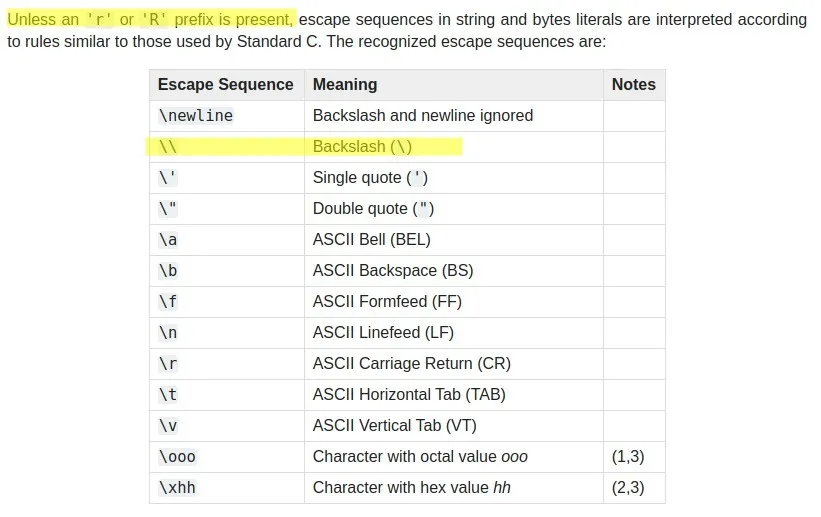
如果你想在字符串中放置一个字面意义的
\,你必须使用\\
为了转义包括点在内的字符串变量中的非字母数字字符,可以使用re.escape:
import re
expression = 'whatever.v1.dfc'
escaped_expression = re.escape(expression)
print(escaped_expression)
输出:
whatever\.v1\.dfc
您可以使用转义表达式来直接查找/匹配字符串。
^.*?\btest\b\.\bthis\b.*?
import re
input_string = "blah blah blah test.this@gmail.com blah blah"
regex_string = "^.*?\\btest\\b\\.\\bthis\\b.*?"
if re.search(regex_string, input_string):
print("match :-)")
else:
print("no match :-(")
这个表达式,
(?<=\s|^)[^.\s]+\.[^.\s]+(?=@)
对于那些特定类型的输入字符串,这也可能有效。
import re
expression = r'(?<=^|\s)[^.\s]+\.[^.\s]+(?=@)'
string = '''
blah blah blah test.this@gmail.com blah blah
blah blah blah test.this @gmail.com blah blah
blah blah blah test.this.this@gmail.com blah blah
'''
matches = re.findall(expression, string)
print(matches)
['test.this']
如果您想简化/修改/探索表达式,可以在regex101.com的右上方面板中找到解释。如果您愿意,您还可以在this link中观看它如何匹配一些示例输入。
\\。来匹配一个点。"blah.tests.zibri.org".match('test\\..*')
null
并且
"blah.test.zibri.org".match('test\\..*')
["test.zibri.org", index: 5, input: "blah.test.zibri.org", groups: undefined]
\w只匹配单个字符 - 你可能想要使用\w+。 - Peter Boughton