假设我有一组点(x,y和大小),我想使用
在我的情况下,
谢谢!
sklearn.cluster.DBSCAN找到我的数据中的聚类及其中心。如果我将每个点视为相同,则没有问题。但实际上,我想要加权中心而不是几何中心(这意味着较大的点应计算比较小的点更多)。我遇到了sample_weight,但我不确定是否需要它。当我使用sample_weight(右侧)时,我得到完全不同的聚类结果,而在不使用它的情况下(左侧),我则得到不同的结果:
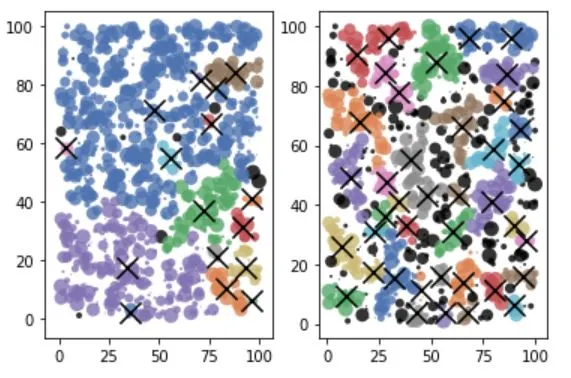
np.repeat(x,w),其中x是我的数据,w是每个点的大小,因此我可以获得与它们的权重成比例的多个点的副本。但是这可能不是一个明智的解决方案,因为我会得到很多数据,对吧?在我的情况下,
sample_weight有用吗?还是有比使用np.repeat更好的解决方案建议?我知道已经有一些关于sample_weight的问题,但我无法确切地了解如何使用它。谢谢!
sklearn.cluster.DBSCAN的一个方法。我使用它的方式是:fit_predict(self, X[, y, sample_weight])。 - Mo Re