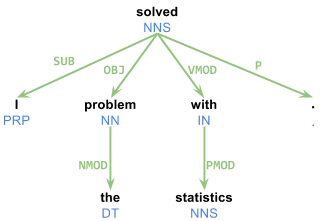
我一直在尝试使用CMU's TurboParser生成的依赖解析树。它运行无误。然而,存在非常少的文档资料。我需要精确地理解他们的解析器输出。例如,句子“I solved the problem with statistics.”会生成以下输出:
1 I _ PRP PRP _ 2 SUB
2 solved _ VBD VBD _ 0 ROOT
3 the _ DT DT _ 4 NMOD
4 problem _ NN NN _ 2 OBJ
5 with _ IN IN _ 2 VMOD
6 statistics _ NNS NNS _ 5 PMOD
7 . _ . . _ 2 P
我没有找到任何文档可以帮助理解各列的含义,以及第二列中创建的索引(2、0、4、2等)。此外,我不知道为什么有两列用于词性标注。任何帮助(或指向外部文档的链接)都将非常有帮助。
附言:如果您想尝试他们的解析器,这里是他们的在线演示。
再附言:请不要建议使用斯坦福的依赖解析输出。我对线性规划算法感兴趣,这不是斯坦福自然语言处理系统的工作内容。