我正在学习系统架构课程,但是我不太理解直接映射高速缓存的工作原理。
我已经搜索了很多地方,但它们用不同的方式解释,让我更加困惑。
我不理解的是什么是标记和索引,以及它们是如何被选择的?
我的讲座解释是: “地址分为两部分 索引(例如15位),用于直接寻址(32k)RAMs 剩余的地址,标记被存储并与传入的标记进行比较。”
这个标记从哪里来?它不能是RAM中内存位置的完整地址,因为与全关联高速缓存相比,这会使直接映射高速缓存无用。
非常感谢。
我正在学习系统架构课程,但是我不太理解直接映射高速缓存的工作原理。
我已经搜索了很多地方,但它们用不同的方式解释,让我更加困惑。
我不理解的是什么是标记和索引,以及它们是如何被选择的?
我的讲座解释是: “地址分为两部分 索引(例如15位),用于直接寻址(32k)RAMs 剩余的地址,标记被存储并与传入的标记进行比较。”
这个标记从哪里来?它不能是RAM中内存位置的完整地址,因为与全关联高速缓存相比,这会使直接映射高速缓存无用。
非常感谢。
好的。 那么让我们首先了解CPU如何与缓存交互。
大致而言,有三层内存-缓存(通常由 SRAM 芯片制成),主内存(通常由 DRAM 芯片制成)和存储(通常为磁性,如硬盘)。每当CPU需要来自特定位置的数据时,它首先搜索缓存以查看是否存在。缓存内存在内存层次结构中最靠近CPU,因此其访问时间最短(成本最高),因此如果CPU正在查找的数据可以在那里找到,则构成'命中',并且从那里获取数据供CPU使用。如果不存在,那么数据必须从主内存移动到缓存中,然后才能被CPU访问(CPU通常仅与缓存交互),这会产生时间惩罚。
因此,为了确定缓存中是否存在数据,应用各种算法。其中之一是直接映射缓存方法。为简单起见,假设存在一个有10个缓存内存位置(编号0到9)和40个主内存位置(编号0到39)的内存系统。这张图片总结了它:
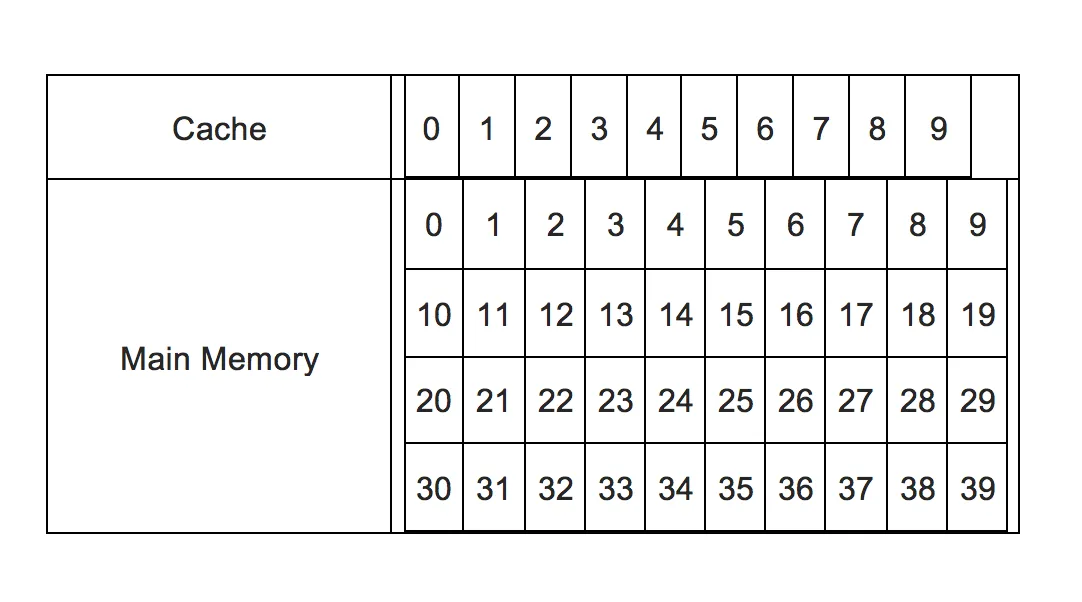
有40个主内存位置可用,但只能容纳最多10个缓存。因此,现在需要通过某种方式将来自CPU的请求重定向到缓存位置。那就有两个问题:
如何重定向? 具体而言,在可预测且随时间不变的情况下如何进行?
如果缓存位置已经填满了一些数据,则来自CPU的传入请求必须确定其所需数据的地址是否与存储在该位置的地址相同。
<RAM Block Address> MOD <Number of Blocks in the Cache>
因此,假设我们有32个RAM块和8个缓存块。<RAM块地址> MOD <缓存中集合的数量>
因此,假设我们有32个RAM块和一个分成4组的缓存(每组有两个块,即总共8个块)。这样,集合0将拥有块0和1,集合1将拥有块2和3,依此类推...TAG | INDEX | OFFSET | DATA 1 | DATA 2 | ... | DATA N
标签将用于查找块,索引将显示块位于哪个集合中,偏移量将选择其右侧的一个字段。
我希望我的理解是正确的,如果不是,请告诉我。