我希望您能为我提供建议,这是否是Google CDN的错误还是我错过了什么。我发现了这个错误大约4个月前,试图联系他们的支持团队,但他们非常粗鲁,以至于我不想在这里谈论那件事。他们接受了,并告诉我他们将把问题发送给后端团队,但之后他们删除了问题跟踪器,并且不再回复我的电子邮件。这就是我在这里询问的主要原因。
问题:
Google CDN随机地不向最终用户提供gzip内容。因此,他们下载了500KB文件而不是约70KB。我无法直接模拟此问题到我的源,但我可以很容易地在Google CDN上产生此问题。
以下是对CDN的示例请求:
请求:
正如您所看到的,我的请求具有accept-encoding:gzip头,但我收到的内容并非gzip。我收到的是500KB而不是70KB。还请注意Age头,该项已被缓存/存在CDN上58422秒!
暂时解决办法
如果我清除CDN缓存,这个问题在接下来的几分钟/小时内就不存在了。过一段时间后,它仍然会出现。而且这个问题并不总是发生,而是随机发生。我有一个系统来解析CDN日志并显示图表,这实际上就是我发现这个错误的方法。
如果问题出在我的源头上,我会很高兴,因为我可以在一分钟内解决,但我认为这是Google CDN的错误。如果有任何更了解CDN技术的人来协助我或来自Google Cloud的人,我将非常高兴。
编辑:
正如我所说,这个问题发生在随机的时间框架内,这是我现在录制的视频,展示了一个“无错误时间框架”。正如您所看到的,每个响应都被压缩。 NO BUG TIME FRAME CDN VIDEO 编辑2:
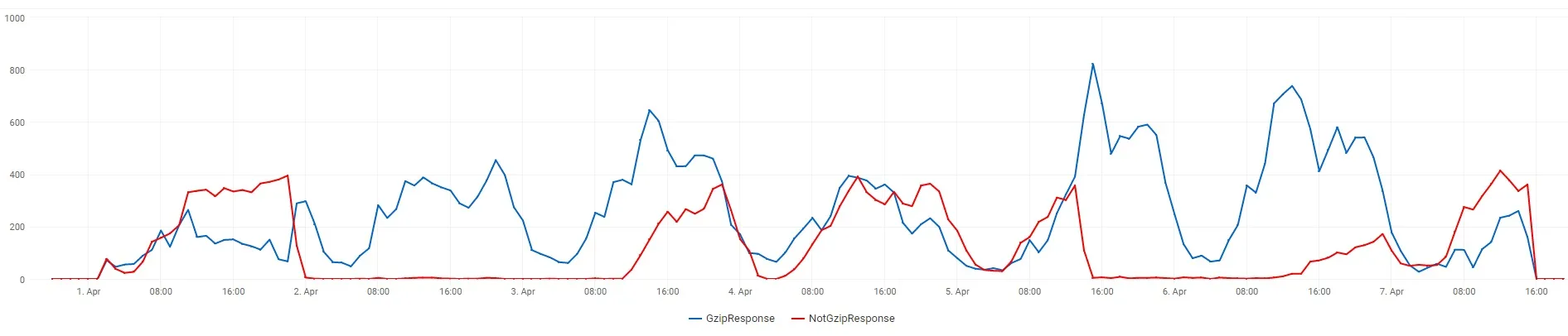
这是一个图表,显示了单个.css URL测试的gzip和非gzip响应数量。
此外,文档还说:
当请求没有'Vary'头时,什么也不会发生。
这是我如何修复它:
问题:
Google CDN随机地不向最终用户提供gzip内容。因此,他们下载了500KB文件而不是约70KB。我无法直接模拟此问题到我的源,但我可以很容易地在Google CDN上产生此问题。
以下是对CDN的示例请求:
请求:
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch, br
Accept-Language:en-US,en;q=0.8,bg;q=0.6,hr;q=0.4,mk;q=0.2,sr;q=0.2
Cache-Control:no-cache
Connection:keep-alive
Cookie: example
Host: example.com
Pragma:no-cache
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36
响应:
Accept-Ranges:bytes
Age:58422
Alt-Svc:clear
Cache-Control:public, max-age=604800
Content-Length:550158
Content-Type:text/css
Date:Tue, 04 Apr 2017 03:45:53 GMT
Expires:Tue, 11 Apr 2017 03:45:53 GMT
Last-Modified:Sun, 19 Mar 2017 01:50:22 GMT
Server:LiteSpeed
Via:1.1 google
正如您所看到的,我的请求具有accept-encoding:gzip头,但我收到的内容并非gzip。我收到的是500KB而不是70KB。还请注意Age头,该项已被缓存/存在CDN上58422秒!
这里是另一台机器(美国)发送的相同请求
请求:
:authority: xxx
:method:GET
:path:/wp-content/themes/365/style.css
:scheme:https
accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
accept-encoding:gzip, deflate, sdch, br
accept-language:en-US,en;q=0.8
cache-control:no-cache
cookie: xxx
pragma:no-cache
upgrade-insecure-requests:1
user-agent:Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
响应:
accept-ranges:bytes
age:58106
alt-svc:clear
cache-control:public, max-age=604800
content-encoding:gzip
content-length:72146
content-type:text/css
date:Tue, 04 Apr 2017 03:49:28 GMT
expires:Tue, 11 Apr 2017 03:49:28 GMT
last-modified:Sun, 19 Mar 2017 01:50:22 GMT
server:LiteSpeed
status:200
vary:Accept-Encoding
via:1.1 google
如您所见,我从我的另一台服务器上获取了一个gzip内容。
我有大量的HAR文件和视频可以证明这个bug,但是让我们保持简单。Google CDN日志可以在GCP仪表板中获得,检查一下它们是什么样子。
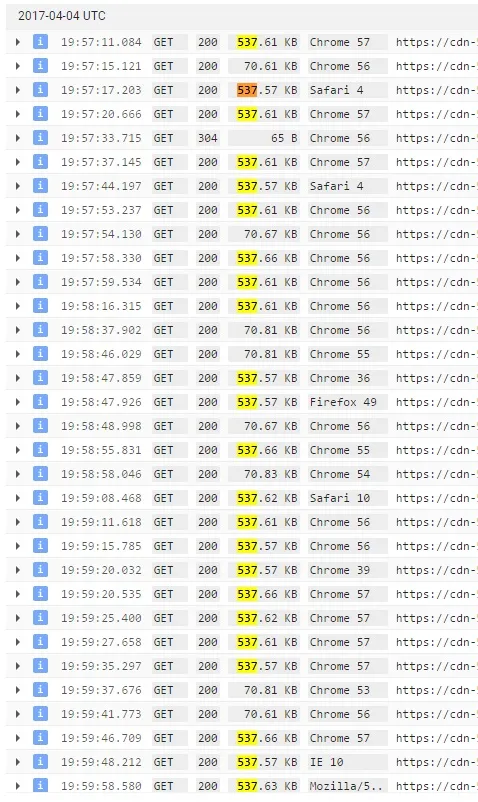
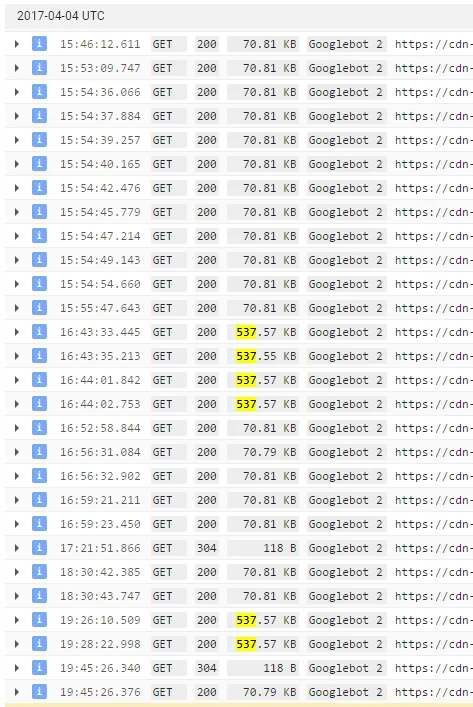
暂时解决办法
如果我清除CDN缓存,这个问题在接下来的几分钟/小时内就不存在了。过一段时间后,它仍然会出现。而且这个问题并不总是发生,而是随机发生。我有一个系统来解析CDN日志并显示图表,这实际上就是我发现这个错误的方法。
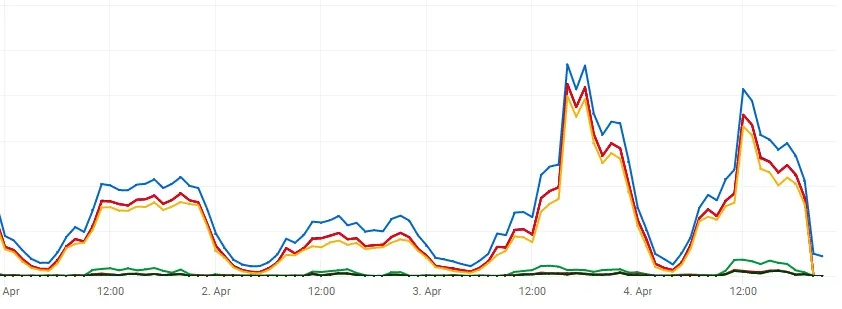
如果问题出在我的源头上,我会很高兴,因为我可以在一分钟内解决,但我认为这是Google CDN的错误。如果有任何更了解CDN技术的人来协助我或来自Google Cloud的人,我将非常高兴。
编辑:
正如我所说,这个问题发生在随机的时间框架内,这是我现在录制的视频,展示了一个“无错误时间框架”。正如您所看到的,每个响应都被压缩。 NO BUG TIME FRAME CDN VIDEO 编辑2:
这是一个图表,显示了单个.css URL测试的gzip和非gzip响应数量。
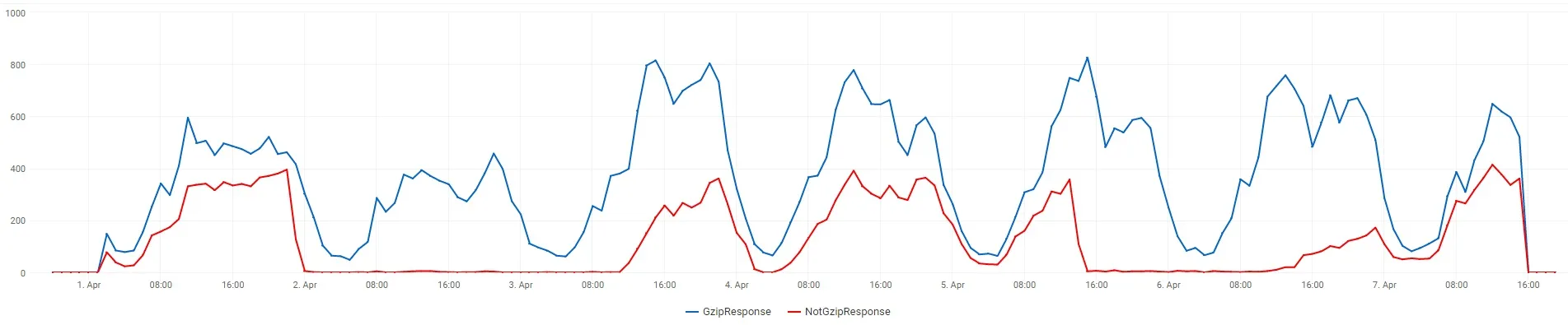
编辑3:
在第一张图像上,线条是可堆叠的,这里是没有堆叠的相同图像。正如您所看到的,有些小时几乎100%的响应没有使用gzip。
编辑4:
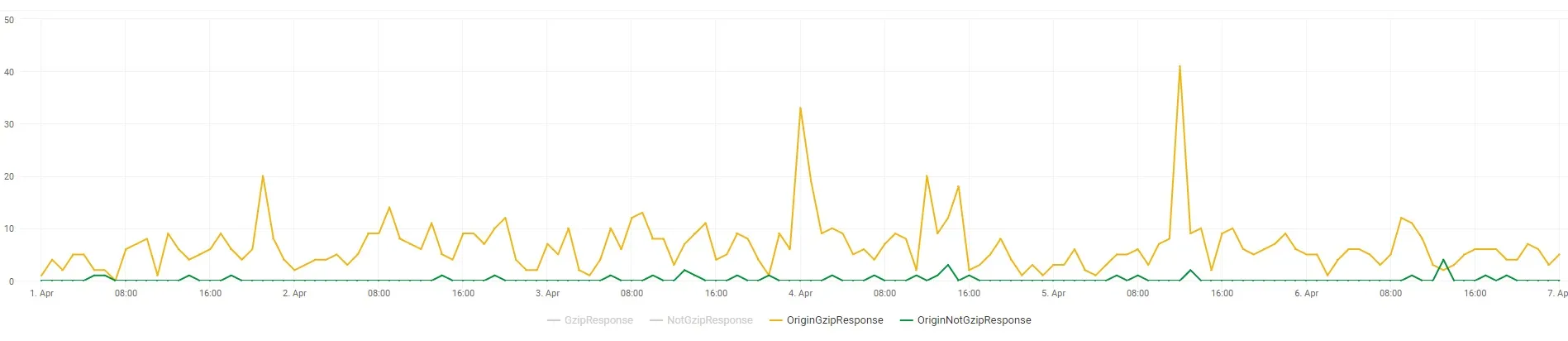
这是同一个CSS文件的原始解析日志。
1060个请求的响应大小在100KB以下。200、304、206响应代码。 32个请求的响应大小超过100KB。200和206响应代码。
编辑5:
分析了4月1日至7日的日志,以下是单个.css URL的一些额外统计数据:
19803个CDN请求使用了>100KB(未压缩)
41004个CDN请求使用了<100KB(gzip)
29个>100KB(未压缩)的缓存来自源站点
924个<100KB(gzip)的缓存来自源站点
423个>100KB(未压缩)的缓存来自缓存
2295个<100KB(gzip)的缓存来自缓存
我很惊讶缓存之间的填充非常有效,太神奇了。
解决方案
源站点没有错误,Google CDN也没有错误。问题在于当Google CDN接收到一个可缓存的实体,并且请求没有发送“Accept-Encoding:gzip”的情况下,Google CDN将存储该未压缩响应并覆盖所有已存储的压缩缓存实体。所以下一次用户尝试获取某个文件(例如.css),Google CDN会回答:
- 我从源站点接收到此文件,并且它没有通过任何方式更改。
- 发送未压缩的响应。
此外,文档还说:
In addition to the request URI, Cloud CDN respects any Vary headers that instances include in responses.
当请求没有'Vary'头时,什么也不会发生。
这是我如何修复它:
<FilesMatch '.(js|css|xml|gz|html|txt|xml|xsd|xsl|svg|svgz)$'>
Header merge Vary Accept-Encoding
</FilesMatch>
curl -s -D - -o /dev/null 'http://example.com/wp-content/themes/365/style.css?42'- elving