my_list = ['Rob Kardashian 00052369 1987-03-17 Reality Star',
'Brooke Barry 00213658 2001-03-30 TikTok Star',
'Bae De Leon 00896351 1997-08-02 Volleyball Player',
'Jonas Blue 02369785 1990-08-02 Music Producer']
我有一个人名、身份证号、出生日期和职业的列表,我想按照姓名、身份证号、出生日期和职业分割每个人。
我尝试了一些愚蠢的方法,但只能完成其中的部分工作,我想知道是否有更好的解决方案?
以下是我的代码:
import re
def remove(my_list):
pattern = '[0-9]'
my_list = [re.sub(pattern, '', i) for i in my_list]
return my_list
print(remove(my_list))
数字已经消失了['罗布·卡戴珊 -- 真人秀明星', '布鲁克·巴里 -- TikTok明星', 'Bae De Leon -- 排球运动员', '乔纳斯·布鲁 -- 音乐制作人']
然后,我删除了“--”
[s.replace(' -- ',' ') for s in remove(my_list)]
['Rob Kardashian Reality Star','Brooke Barry TikTok Star','Bae De Leon Volleyball Player','Jonas Blue Music Producer']
我期望的输出将是一个数据框:
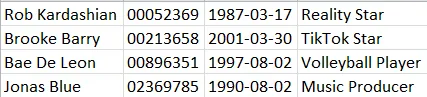
pd.DataFrame(my_list)
感谢您的帮助。