请考虑以下字符串:
s="""A25-54 plus affinities targeting,Demo (AA F21-54),
A25-49 Artist Affinity Targeting,M21-49 plus,plus plus A 21+ targeting"""
我希望修复我的模式,目前它无法从字符串中提取所有年龄组(当前输出中缺少A 21+)。
当前尝试:
import re
re.findall(r'(?:A|A |AA F|M)(\d+-\d+)',s)
输出:
['25-54', '21-54', '25-49', '21-49'] #doesnot capture the last group A 21+
预期输出:
['A25-54','AA F21-54','A25-49','M21-49','A 21+']
如您所见,我希望在输出结果中包含最后一个组,即目前缺失的A 21+。
另外,如果可以获取与捕获组相关联的字符串。目前我的输出除了未捕获所有的组外,还没有在年龄组之前包含字符串。例如:我想要'A25-54'而不是'25-54',我猜这是因为?:。
非常感谢能得到任何帮助。
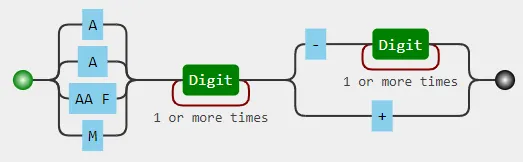
(?:A(?: |A F)?|M)\d+(?:-\d+|\+)。虽然不太易读,但它遵循最佳实践:组内的每个替代项都不应与其他组在同一位置匹配。 - Wiktor Stribiżew