我有100个结构体,看起来像这样:
struct s00 { char data[30]; };
struct s01 { char data[30]; };
struct s02 { int data[10]; };
struct s03 { double data[5]; };
struct s04 { float data[20]; };
struct s05 { short data[15]; };
struct s06 { char data[7]; };
struct s07 { int data[19]; };
struct s08 { double data[11]; };
struct s09 { float data[5]; };
struct s10 { char data[52]; };
//...
struct s99 { char data[12]; };
typedef struct s00 s00;
typedef struct s01 s01;
typedef struct s02 s02;
//...
typedef struct s99 s99;
我希望在编译时找到这些结构体中最大的
sizeof。我尝试使用类似于这样的比较宏: #define LARGER(a, b) ((a) > (b) ? (a) : (b))
然后使用此来构建最终定义,其中将包含结果:
#define MAX_SIZEOF (LARGER(sizeof(s00), \
LARGER(sizeof(s01), \
LARGER(sizeof(s02), \
LARGER(sizeof(s03), \
LARGER(sizeof(s04), \
LARGER(sizeof(s05), \
LARGER(sizeof(s06), \
LARGER(sizeof(s07), \
LARGER(sizeof(s08), \
LARGER(sizeof(s09), \
LARGER(sizeof(s10), \
//...
sizeof(s99))) /*...*/ ))
然而,编译器空间不足:
错误C1060 编译器堆栈空间不足
这很合理,因为这个 #define 必须跟踪许多数字,因为它只是替换文本。具体来说,MAX_SIZEOF 中找到的整数数量是指数级的,可以描述为:
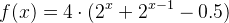
其中x等于涉及的结构体数量。假设一个整数占用4字节,编译器需要分配30.4个十的21次方字节来计算此宏(如果我的计算正确的话)。我的系统最多只能处理17个结构体(786430个数字,3.14兆字节)。
我不确定如何在C中找到高效的解决方案。
在C++中,我可以很容易地使用constexpr实现这一点,而且没有任何编译问题:
constexpr size_t LARGER(size_t a, size_t b) {
return a > b ? a : b;
}
constexpr size_t MAX_SIZEOF() {
return
LARGER(sizeof(s00), \
LARGER(sizeof(s01), \
LARGER(sizeof(s02), \
LARGER(sizeof(s03), \
LARGER(sizeof(s04), \
LARGER(sizeof(s05), \
LARGER(sizeof(s06), \
LARGER(sizeof(s07), \
LARGER(sizeof(s08), \
LARGER(sizeof(s09), \
LARGER(sizeof(s10), \
//...
sizeof(s99))/*...*/)));
但是,我必须在这里仅使用C语言。...感谢任何想法!
c++如何实现constexpr,在编译时评估您在c中尝试的内容,而不发出任何警告声? - izac89