我正在学习R语言中“vars”库中的范例。除了vignette的Table 5 here之外,我已经理解了大部分的范例。
通过运行下面的代码,我看到了协整向量和载荷点估计是如何得出的,但我不明白t统计量是从哪里得出的。
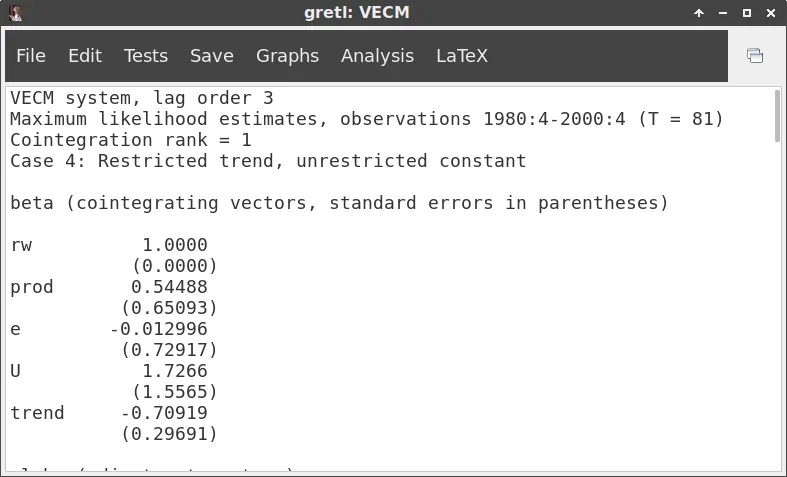
我运行了这段代码: library("vars") data("Canada") Canada <- Canada[, c("prod", "e", "U", "rw")] vecm <- ca.jo(Canada[, c("rw", "prod", "e", "U")], type = "trace", ecdet = "trend", K = 3, spec = "transitory") vecm.r1 <- cajorls(vecm, r = 1)
并得到了这些特征向量和权重。
通过运行下面的代码,我看到了协整向量和载荷点估计是如何得出的,但我不明白t统计量是从哪里得出的。
我运行了这段代码: library("vars") data("Canada") Canada <- Canada[, c("prod", "e", "U", "rw")] vecm <- ca.jo(Canada[, c("rw", "prod", "e", "U")], type = "trace", ecdet = "trend", K = 3, spec = "transitory") vecm.r1 <- cajorls(vecm, r = 1)
并得到了这些特征向量和权重。
Eigenvectors, normalised to first column:
(These are the cointegration relations)
rw.l1 prod.l1 e.l1 U.l1 trend.l1
rw.l1 1.00000000 1.0000000 1.0000000 1.000000 1.0000000
prod.l1 0.54487553 -3.0021508 0.7153696 -7.173608 0.4087221
e.l1 -0.01299605 -3.8867890 -2.0625220 -30.429074 -3.3884676
U.l1 1.72657188 -10.2183404 -5.3124427 -49.077209 -5.1326687
trend.l1 -0.70918872 0.6913363 -0.3643533 11.424630 0.1157125
Weights W:
(This is the loading matrix)
rw.l1 prod.l1 e.l1 U.l1 trend.l1
rw.d -0.084814510 0.048563997 -0.02368720 -0.0016583069 5.722004e-12
prod.d -0.011994081 0.009204887 -0.09921487 0.0020567547 -7.478364e-12
e.d -0.015606039 -0.038019447 -0.01140202 -0.0005559337 -1.229460e-11
U.d -0.008659911 0.020499657 0.02896325 0.0009140795 1.103862e-11
请告诉我如何在代码中找到表5中正确的alpha和beta值。
但我不知道表5中的t统计量是如何在代码中推导出来的。有没有人能指点我一下?
谢谢,
詹姆斯
df=orls$rlm$df.residualbeta的自由度。 alpha的自由度是多少? 我们如何计算alpha的自由度? 我们如何计算alpha的p值? 如果您能包含您给出的Gretl代码的截图,那就更好了。非常感谢。 - Erdogan CEVHER