我正在练习我的SQL技能并尝试解决一些练习题。
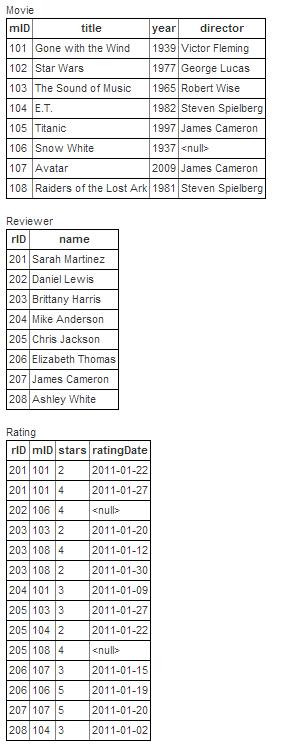
问题: 在所有同一评审人两次评价同一部电影 (存储在rating表中) 且第二次给出更高的评分 (rating.stars) 的情况下,返回评审人的姓名 (存储在reviewer表中) 和电影的标题 (存储在movie表中)。
SELECT
r.NAME AS reviewer
,m.Title AS movietitle
FROM rating ra
LEFT JOIN movie m ON m.mID = ra.mID
LEFT JOIN reviewer r ON r.rID = ra.rID
LEFT JOIN
(
SELECT
ra.rID
,ra.mID
,MAX(ra.RatingDate) AS MaxDate
,MIN(ra.RatingDate) AS MinDate
,MAX(ra.stars) AS MaxStars
,MIN(ra.stars) AS MinStars
FROM Rating ra
GROUP BY ra.rID, ra.mID
HAVING MAX(ra.stars) <> MIN(ra.stars) and COUNT(*) = 2
) rs ON ra.rID = rs.rID AND ra.mID = rs.mID
WHERE
ra.Ratingdate = rs.MaxDate
AND ra.stars = rs.MaxStars
对于上述查询解决方案,我尝试并且认为是正确的。
- 这是解决问题最清晰的方式吗?
- 有没有解决相同问题的快捷方法?
- 这些问题的实际名称是什么?我在标题上列出了一个名称,“只有当A>B时才选择X,在此范围内的A和B值是变量”,是否有更好的分类这些类型的问题的方式或者它们已经在某些书籍或社区中分类了?
参考文献
http://sqlfiddle.com/#!2/8031b/1509
http://i42.photobucket.com/albums/e311/indiecoding/data_zpsd505fa8a.png
{kind=link}
WHERE子句解决了那个问题。虽然它实际上应该在ON子句中,因为它比较的是两个表/子查询。 - Barmar