我最近读到,C和C++中的有符号整数溢出会导致未定义行为:
如果在表达式求值过程中,结果在其类型的可表示值范围内没有数学定义或不在该类型的可表示值范围内,则行为是未定义的。
我目前正在尝试理解此处未定义行为的原因。我认为未定义行为发生在此处,是因为整数在变得太大而无法适应基础类型时开始操纵其周围的内存。
因此,我决定在Visual Studio 2015中编写一个小测试程序来使用以下代码测试该理论:
#include <stdio.h>
#include <limits.h>
struct TestStruct
{
char pad1[50];
int testVal;
char pad2[50];
};
int main()
{
TestStruct test;
memset(&test, 0, sizeof(test));
for (test.testVal = 0; ; test.testVal++)
{
if (test.testVal == INT_MAX)
printf("Overflowing\r\n");
}
return 0;
}
我在这里使用了一个结构来防止在调试模式下出现任何 Visual Studio 的保护措施,例如堆栈变量的临时填充等。
这个无限循环应该会导致 test.testVal 的多次溢出,事实上确实如此,但除了溢出本身外没有任何后果。
在运行溢出测试时,我查看了内存转储,结果如下(test.testVal 的内存地址为 0x001CFAFC):
0x001CFAE5 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x001CFAFC 94 53 ca d8 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
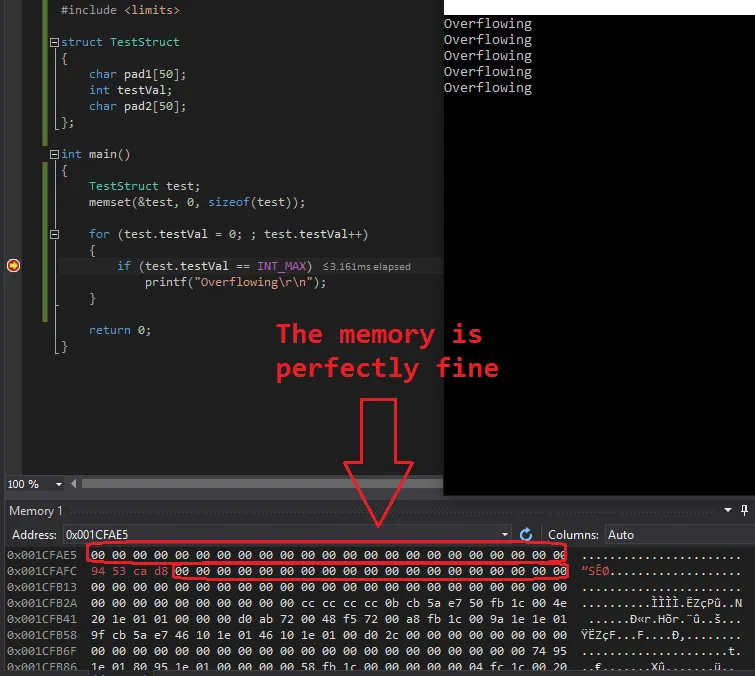
如您所见,持续溢出的int周围的内存仍然“未受损”。我使用类似的输出进行了多次测试。从未有任何关于溢出int周围内存的损坏。
这里发生了什么?为什么变量test.testVal周围的内存没有受到破坏?这如何导致未定义的行为?
我正在尝试理解我的错误,以及为什么在整数溢出期间没有发生内存破坏。