我在我的.NET 7项目中使用最新版本的SQL Server和EF Core。
我有一个名为“Deposits”的表,其中有400万行。我遇到了一个小问题,想知道如何解决它。
我有一个非常简单的查询:
我注意到执行时间非常长(略超过10秒)。
经过一番思考,我交换了查询中的条件:
之前:
查询开始执行大约8毫秒(附上截图)。
此外,通过SSMS执行没有任何区别。
我有一个名为“Deposits”的表,其中有400万行。我遇到了一个小问题,想知道如何解决它。
我有一个非常简单的查询:
var deposits = await dataContext.Deposits
.Where(d => d.OwnerId == userId
&& d.DepositReason == DepositReason.Purchase)
.Select(p => p.Id)
.OrderByDescending(id => id)
.ToListAsync();
我注意到执行时间非常长(略超过10秒)。
经过一番思考,我交换了查询中的条件:
之前:
d.OwnerId == userId
&& d.DepositReason == DepositReason.Purchase
之后:
d.DepositReason == DepositReason.Purchase
&& d.OwnerId == userId
查询开始执行大约8毫秒(附上截图)。
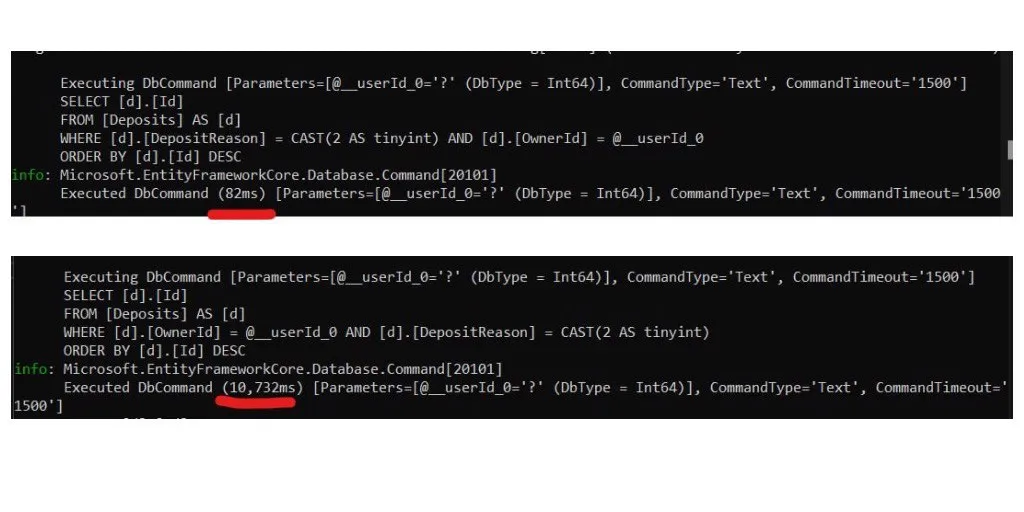
此外,通过SSMS执行没有任何区别。
select *
from deposits
where DepositReason = 2
and OwnerId = 1
或者
select *
from deposits
where OwnerId = 1
and DepositReason = 2
速度总是很快。
我真的很想知道如何处理这样的异常。如果有人了解这是如何工作的以及可以做些什么,请分享你的知识。谢谢!
最慢的查询:
SELECT [d].[Id] FROM [Deposits] AS [d] WHERE [d].[OwnerId] = @__userId_0 AND [d].[DepositReason] = CAST(2 AS tinyint) ORDER BY [d].[Id] DESC
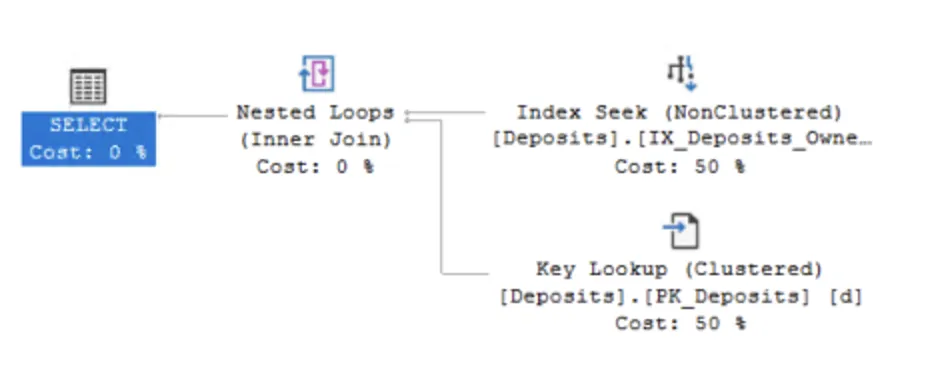
OwnerId在deposits表中有比其他人更多的行。如果计划编译用于行数较少的OwnerId,则会编译一个带有非覆盖索引查找和查找操作的计划;如果编译用于不同的OwnerId,则可能会进行扫描操作,以及在这里出现了ORDER BY语句可能需要排序。您需要获取“慢速”和“快速”情况下的执行计划。这是您可以从查询存储(Query Store)中获取的信息。 - Martin Smithwhere子句中谓词的顺序并不重要。此外,看起来您没有索引可以同时覆盖两个谓词,所以始终使用外键的索引,而不考虑其他谓词值的基数。也许您应该查看并添加一些影响计划的提示。无论如何,这纯粹是SqlServer的问题,与EF Core无关。 - Ivan Stoevoption (recompile),通常可以解决此类问题。 - Ivan Stoev