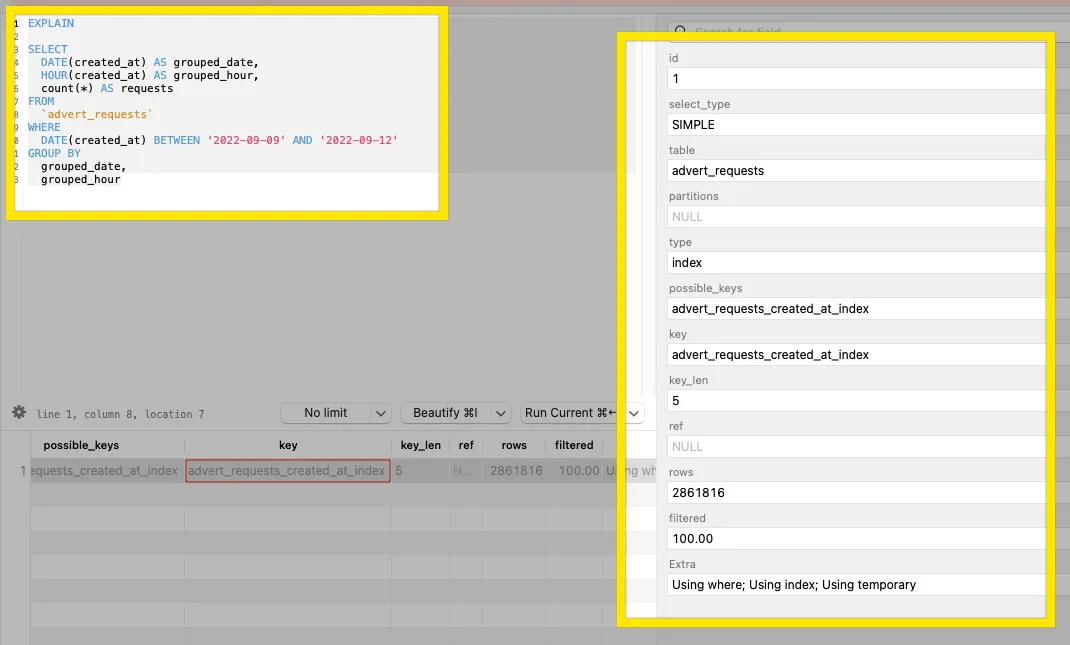
EXPLAIN 显示的是
type: index,这是一种索引扫描。也就是说,它正在使用索引,但是像表扫描一样迭代索引中的每个条目,而不仅仅是与条件匹配的行。这得到了
rows: 2861816 的支持,它告诉您优化器估计将要检查的索引条目数量(这是一个粗略的数字)。这比仅检查与条件匹配的行要昂贵得多,而这也是我们从索引中寻求的好处。
那么为什么会这样呢?
当您在搜索中使用索引列上的任何函数时,就会出现这种情况:
WHERE
DATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12'
这破坏了索引减少检查行数的好处。
MySQL 的优化器对函数结果没有任何智能提示,因此无法推断返回值的顺序是否与索引相同。因此,它不能利用索引排序来缩小搜索范围。你和我都知道 DATE(created_at) 应该与created_at 相同顺序,但查询优化器不知道这一点。还有其他像 MONTH(created_at) 这样的函数,其结果明显不是按排序顺序的,MySQL 优化器不尝试知道哪个函数的结果可靠地排序。
要修复查询,可以尝试以下两种方法之一:
使用表达式索引。这是 MySQL 8.0 中的新特性:
ALTER TABLE `advert_requests` ADD INDEX ((DATE(created_at)))
注意多余的一对括号。定义表达式索引时需要这些括号。索引条目是该函数或表达式的结果,而不是列的原始值。
如果在查询中使用同样的表达式,则优化器会识别并使用该索引。
mysql> explain SELECT DATE(created_at) AS grouped_date, HOUR(created_at) AS grouped_hour, count(*) AS requests FROM `advert_requests` WHERE DATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12' GROUP BY grouped_date, grouped_hour\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: advert_requests
partitions: NULL
type: range <
possible_keys: functional_index
key: functional_index
key_len: 4
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where; Using temporary
如果您使用的是MySQL 5.7版本,则无法直接使用表达式索引,但是您可以使用虚拟列并在虚拟列上定义索引:
ALTER TABLE advert_requests
ADD COLUMN created_at_date DATE AS (DATE(created_at)),
ADD INDEX (created_at_date);
优化器识别表达式的技巧仍然有效。
如果您使用的MySQL版本早于5.7,无论如何都应该升级。MySQL 5.6及更早版本已经过了其生命周期,是安全风险。
第二件事是重构查询,使created_at列不在函数内部。
WHERE
created_at >= '2022-09-09' AND created_at < '2022-09-13'
当将日期时间与日期值进行比较时,日期值默认为00:00:00.000时间。要包含每一秒的时间戳,直到2022-09-12 23:59:59.999,更简单的方法是只使用< '2022-09-13'。
这个语句的EXPLAIN显示它使用了现有的created_at索引。
mysql> explain SELECT DATE(created_at) AS grouped_date, HOUR(created_at) AS grouped_hour, count(*) AS requests FROM `advert_requests` WHERE created_at >= '2022-09-09' AND created_at < '2022-09-13' GROUP BY grouped_date, grouped_hour\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: advert_requests
partitions: NULL
type: range <
possible_keys: created_at
key: created_at
key_len: 6
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition; Using temporary
这个解决方法适用于旧版本的MySQL以及5.7和8.0版本。
WHERE条件。将其拆分为日期和小时进行分组是昂贵的。 - BarmarDATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12'替换为created_at BETWEEN '2022-09-08 23:59:59' AND '2022-09-12 23:59:59',并检查是否会产生差异。 - Ergest Basha