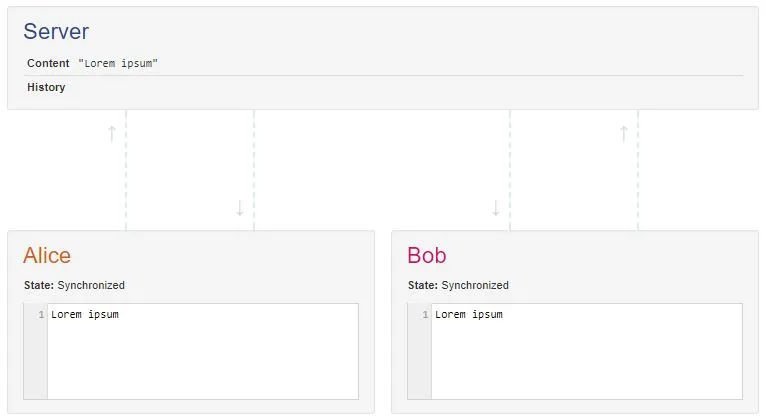
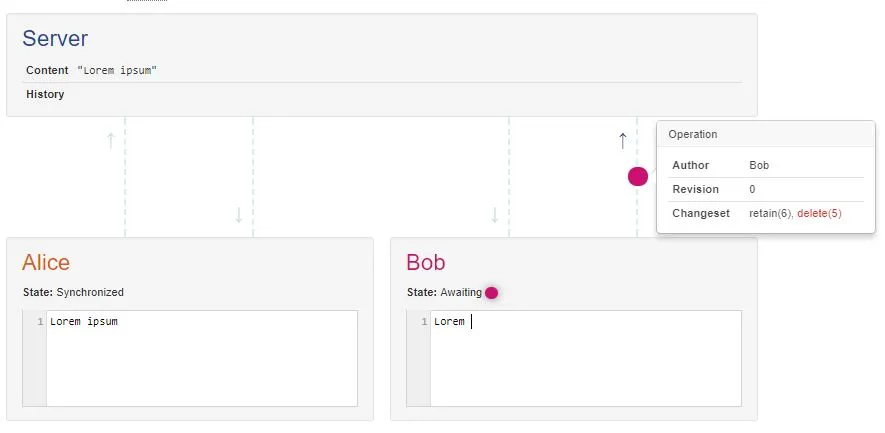
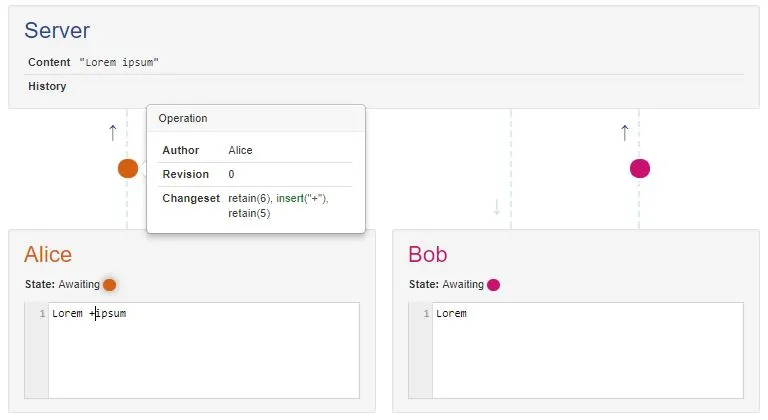
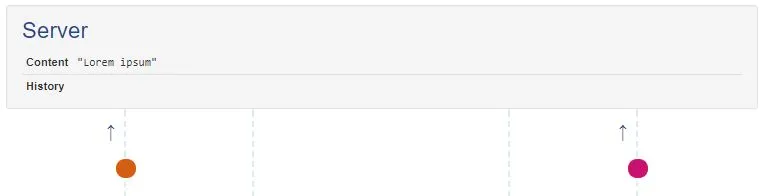
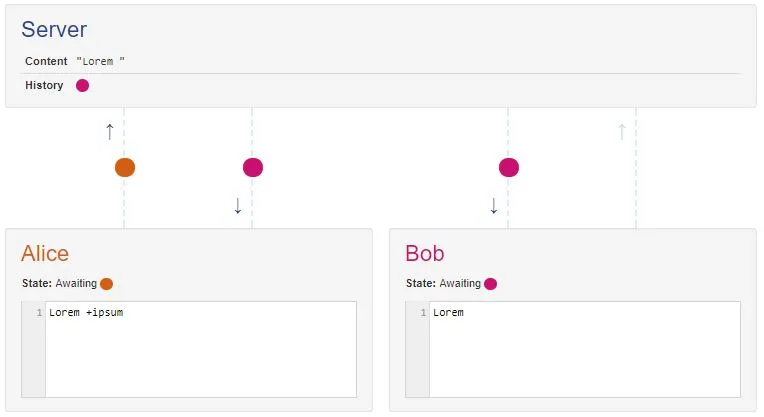
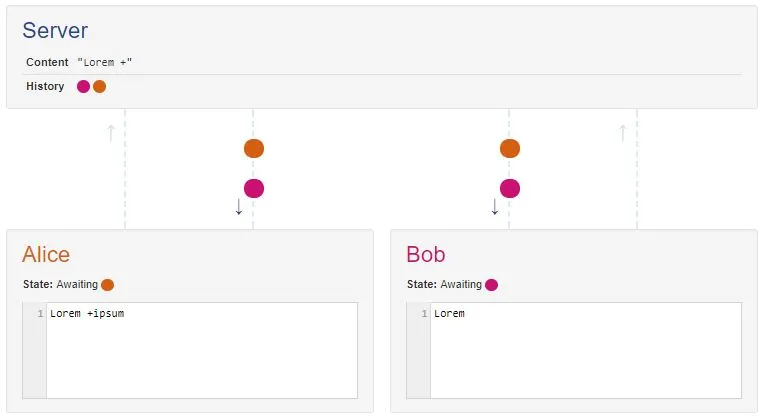
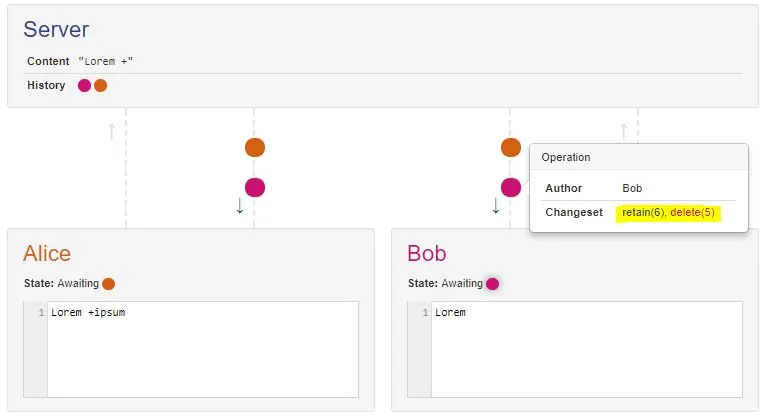
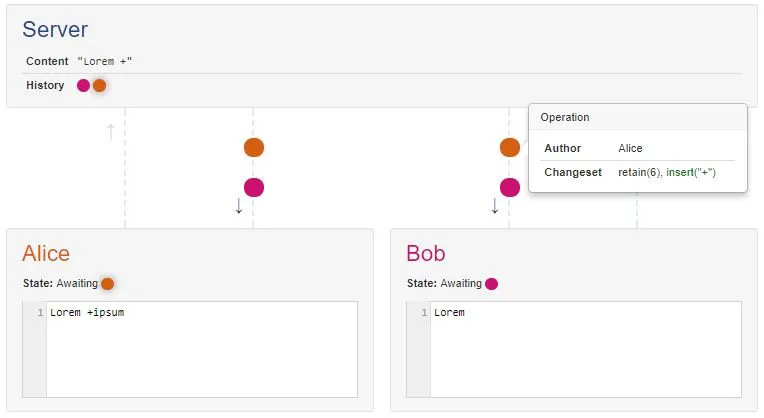
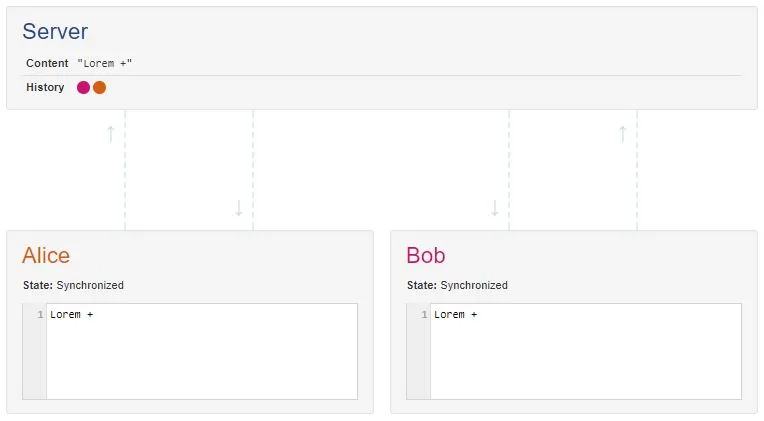
今天尝试了这个实验:为Google文档打开了两个离线编辑器。在一个编辑器中,我加粗了第一个单词。在另一个编辑器中,我删除了它。无论我先打开哪个客户端,这个单词总是被删除。
首先,为什么会出现这种情况 - 我理解操作转换的顺序很重要?在两个人分别输入 "a" 和 "b" 的简单例子中,如果服务器首先接收到 "a",它将通过将第二个人的 "b" 事件转换为 "移动一个空格,然后添加b" 事件来强制输出 "ab",反之亦然。
其次,如果顺序不重要,那么 Google 文档为什么选择删除而不是其他方式呢?或者原因主要是为用户简单考虑?
首先,为什么会出现这种情况 - 我理解操作转换的顺序很重要?在两个人分别输入 "a" 和 "b" 的简单例子中,如果服务器首先接收到 "a",它将通过将第二个人的 "b" 事件转换为 "移动一个空格,然后添加b" 事件来强制输出 "ab",反之亦然。
其次,如果顺序不重要,那么 Google 文档为什么选择删除而不是其他方式呢?或者原因主要是为用户简单考虑?