在非递减(正)整数序列中,当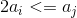 时,可以从该序列中删除两个元素。最多可以从此序列中删除多少对元素?
时,可以从该序列中删除两个元素。最多可以从此序列中删除多少对元素?
我想放置一些图形,但由于声望点数<10-我不能。
(我指的是一开始的一个latex)
时,可以从该序列中删除两个元素。最多可以从此序列中删除多少对元素?
因此,我想到了以下解决方案:
- 将给定序列分为两部分(第一部分和第二部分)。
- 为它们中的每一个分配迭代器 - 分别为it_first := 0和it_second := 0,count := 0
- 当it_second != second.length时
- 如果2 * first[it_first] <= second[it_second]
- count++,it_first++,it_second++
- 否则
- it_second++
- 如果2 * first[it_first] <= second[it_second]
- count就是答案
例子:
count := 0
[1,5,8,10,12,13,15,24] --> first := [1,5,8,10], second := [12,13,15,24]
2 * 1 ?< 12 --> true, count++, it_first++ and it_second++
2 * 5 ?< 13 --> true, count++, it_first++ and it_second++
2 * 8 ?< 15 --> false, it_second++
8 ?<24 --> true, count ++it_second reach the last element - END.
count == 3
线性复杂度(最坏情况下没有要删除的元素。n/2个元素与n/2个元素进行比较)。 所以我的缺失部分是算法的“正确性”-我已经读了关于贪心算法证明的文章-但大多数都是树,我找不到类比。任何帮助将不胜感激。谢谢!
编辑:
通过正确性,我指的是: *它可以正常工作 *它无法更快地完成(在logn或常数中)
[1, 2, 4, 9],[4, 9]也可以是这样的一对。或者像你的例子中,[12, 24]也可以是这样的一对。 - Harsh Gupta