我有这样的文本:
每行都是新的:
tom
tim
john
will
tod
hello
test
ttt
three
我想删除每三行数据,以上例为例,我想删除:john,hello,three
我知道这需要使用一些正则表达式,但是我不太擅长!
我尝试过:
Search: ([^\n]*\n?){3} //3 in my head to remove every third
Replace: $1
我尝试过其他的方式,比如使用
\n\r等。但我对正则表达式掌握得不是很好。我认为前面的尝试已经很接近了。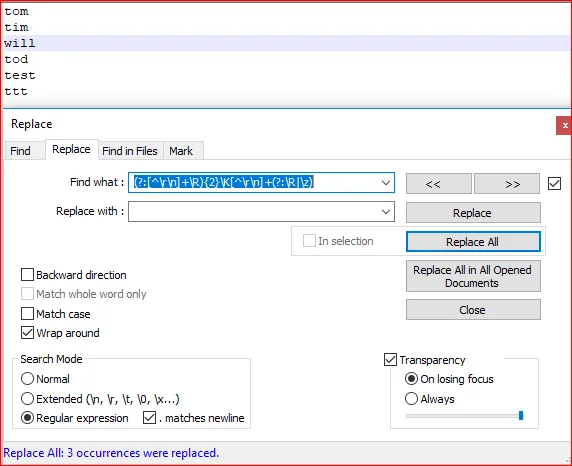
(.*?)\n(.*?)\n(.*)\n进行搜索,并用\1\n\2\n替换它。 - Sahil Gulati