什么是Hi/Lo算法?
我在NHibernate的文档中找到了它(这是生成唯一键的一种方法,第5.1.4.2节),但我没有找到一个好的解释它如何工作。
我知道NHibernate处理它,我不需要知道内部细节,但我只是很好奇。
什么是Hi/Lo算法?
我在NHibernate的文档中找到了它(这是生成唯一键的一种方法,第5.1.4.2节),但我没有找到一个好的解释它如何工作。
我知道NHibernate处理它,我不需要知道内部细节,但我只是很好奇。
除了Jon的答案之外:
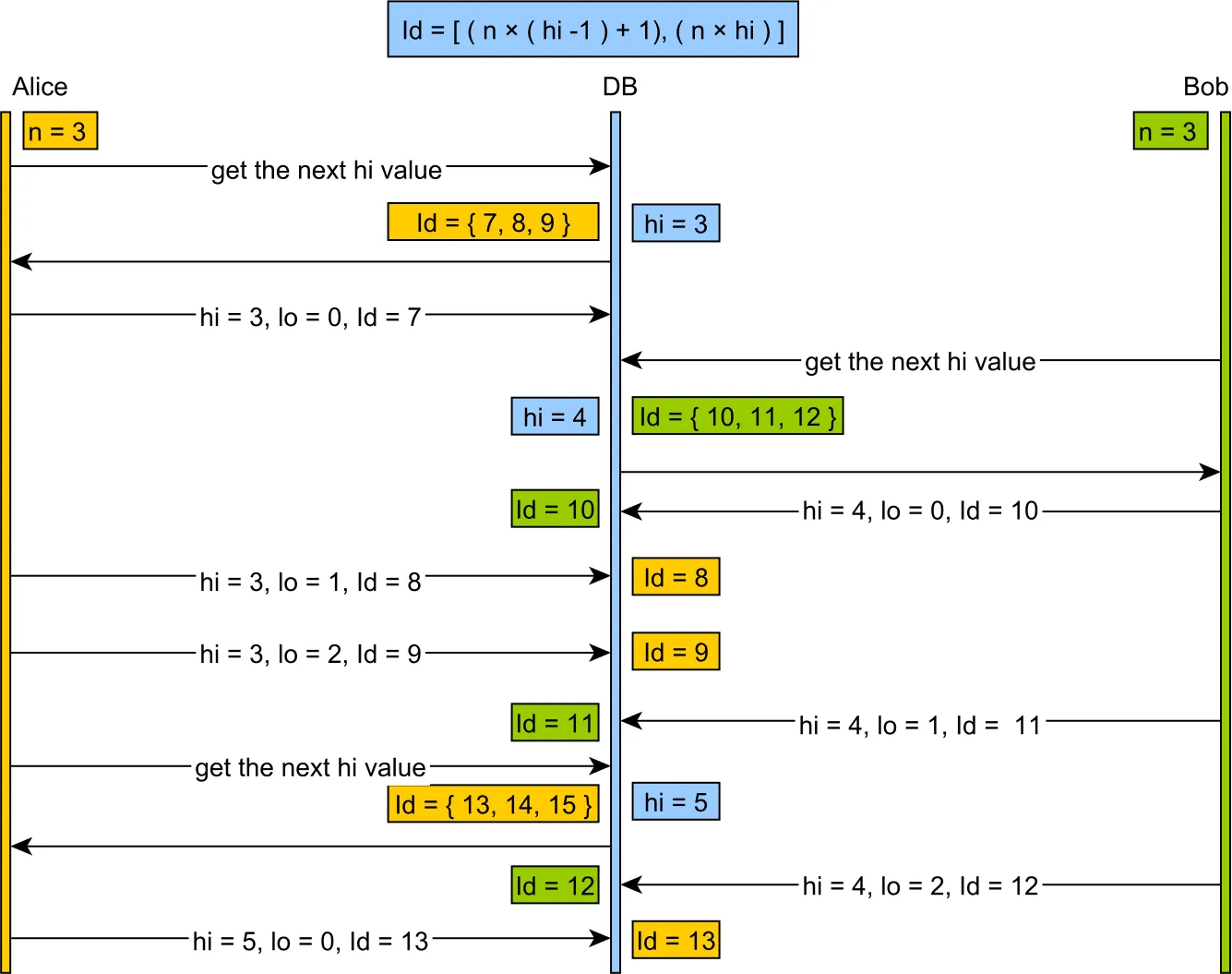
它被用于能够脱机工作。客户端可以向服务器请求一个高号码,并自己增加对象创建低号码。在低号范围用尽之前,不需要联系服务器。
The hi token is assigned by the database, and two concurrent calls are guaranteed to see unique consecutive values
Once a hi token is retrieved we only need the incrementSize (the number of lo entries)
The identifiers range is given by the following formula:
[(hi -1) * incrementSize) + 1, (hi * incrementSize) + 1)
and the “lo” value will be in the range:
[0, incrementSize)
being applied from the start value of:
[(hi -1) * incrementSize) + 1)
When all lo values are used, a new hi value is fetched and the cycle continues
同时,这种视觉呈现方式也非常易于理解:
虽然 hi/lo 优化器对于优化标识符生成来说很好,但是它与其他向数据库插入行的系统不兼容,而这些系统并不知道我们的标识符策略。
Hibernate 提供了 pooled-lo 优化器,它提供了 hi/lo 生成器策略的优点,同时也提供了与其他第三方客户端的互操作性,这些客户端并不知道这个序列分配策略。
由于既高效又可与其他系统互操作,所以 pooled-lo 优化器比传统的 hi/lo 标识符策略更好。
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "name") @SequenceGenerator(name="name", sequenceName = "name_seq", allocationSize=100)来生成我的ID。 - Stefan Golubović, (hi * incrementSize) + 1)... 它应该是, hi * incrementSize),对吗? - HuiaganLo是一种缓存分配器,将键空间划分为大块,通常基于某些机器字大小,而不是人类可能明智选择的有意义的大小范围(例如一次获取200个键)。
使用Hi-Lo往往会在服务器重启时浪费大量的键,并生成大量不友好的键值。
比Hi-Lo分配器更好的是“线性块”分配器。它使用类似的基于表格的原理,但分配小巧便利的块并生成漂亮的人类友好的值。
create table KEY_ALLOC (
SEQ varchar(32) not null,
NEXT bigint not null,
primary key (SEQ)
);
为了分配接下来的200个键(然后在服务器上保持为一个范围并根据需要使用):
select NEXT from KEY_ALLOC where SEQ=?;
update KEY_ALLOC set NEXT=(old value+200) where SEQ=? and NEXT=(old value);
如果您可以执行此事务(使用重试处理争用),则已分配200个密钥,并且可以根据需要分发它们。
仅使用20的块大小,此方案比从Oracle序列中分配快10倍,可在所有数据库之间100%移植。分配性能与hi-lo相当。
与Ambler的想法不同,它将键空间视为连续的线性数字线。
这避免了复合键的冲动(这从未是一个好主意),并在服务器重新启动时避免浪费整个lo-words。它生成“友好”的、人类规模的关键值。
相比之下,Ambler先生的想法分配高16或32位,并生成大型、不友好的关键值,因为高位单词递增。
分配的密钥的比较:
Linear_Chunk Hi_Lo
100 65536
101 65537
102 65538
.. server restart
120 131072
121 131073
122 131073
.. server restart
140 196608
在设计方面,他的解决方案在数轴上基本上比Linear_Chunk复杂得多(包括复合键、大型hi_word乘积),同时却没有获得任何比较优势。
Hi-Lo设计早在OO映射和持久化中就出现了。如今,像Hibernate这样的持久化框架提供更简单、更好的分配器作为默认值。