我正在开发一些CUDA程序,希望使用常量内存加速计算,但使用常量内存后我的代码变慢了约30%。
我知道常量内存适用于向整个线程束广播读取,我认为我的程序可以利用它的优势。
以下是常量内存代码:
可能会导致线程“失步”,然后它们将无法利用常量内存读取的广播优势,因此我尝试在读取常量内存之前调用__syncthreads();,但是这并没有改变任何事情。
有什么问题吗?提前感谢!
系统:
CUDA驱动程序版本:5.0
CUDA能力:2.0
参数:
顶点数:约250万个
平面数:1024
结果:
常量内存版本:46毫秒
全局内存版本:35毫秒
编辑:
因此,我尝试了许多方法来使常量内存更快,例如:
1)注释掉两个全局内存读取以查看它们是否有任何影响,但它们没有。 全局内存仍然更快。
2)每个线程处理更多的顶点(从8到64),以利用CM缓存。 这甚至比每个线程一个顶点还慢。
2b)使用共享内存存储位移和顶点-在开始时加载所有位移和顶点,处理并保存所有位移。 再次比显示的CM示例慢。
经过这次经历,我真的不理解CM读取广播如何工作以及如何在我的代码中正确“使用”它。 这段代码可能无法通过CM进行优化。
编辑2:
调整了一天后,我尝试了:
3)使用内存协调处理每个线程的更多顶点(8到64)(每个线程的增量相等于系统中的总线程数)-这比增量等于1的效果更好,但仍然没有加速。
4)替换此if语句
我知道常量内存适用于向整个线程束广播读取,我认为我的程序可以利用它的优势。
以下是常量内存代码:
__constant__ float4 constPlanes[MAX_PLANES_COUNT];
__global__ void faultsKernelConstantMem(const float3* vertices, unsigned int vertsCount, int* displacements, unsigned int planesCount) {
unsigned int blockId = __mul24(blockIdx.y, gridDim.x) + blockIdx.x;
unsigned int vertexIndex = __mul24(blockId, blockDim.x) + threadIdx.x;
if (vertexIndex >= vertsCount) {
return;
}
float3 v = vertices[vertexIndex];
int displacementSteps = displacements[vertexIndex];
//__syncthreads();
for (unsigned int planeIndex = 0; planeIndex < planesCount; ++planeIndex) {
float4 plane = constPlanes[planeIndex];
if (v.x * plane.x + v.y * plane.y + v.z * plane.z + plane.w > 0) {
++displacementSteps;
}
else {
--displacementSteps;
}
}
displacements[vertexIndex] = displacementSteps;
}
全局内存代码相同,但多了一个参数(指向平面数组的指针),并使用它代替全局数组。
我认为那些第一次读取全局内存的操作
float3 v = vertices[vertexIndex];
int displacementSteps = displacements[vertexIndex];
可能会导致线程“失步”,然后它们将无法利用常量内存读取的广播优势,因此我尝试在读取常量内存之前调用__syncthreads();,但是这并没有改变任何事情。
有什么问题吗?提前感谢!
系统:
CUDA驱动程序版本:5.0
CUDA能力:2.0
参数:
顶点数:约250万个
平面数:1024
结果:
常量内存版本:46毫秒
全局内存版本:35毫秒
编辑:
因此,我尝试了许多方法来使常量内存更快,例如:
1)注释掉两个全局内存读取以查看它们是否有任何影响,但它们没有。 全局内存仍然更快。
2)每个线程处理更多的顶点(从8到64),以利用CM缓存。 这甚至比每个线程一个顶点还慢。
2b)使用共享内存存储位移和顶点-在开始时加载所有位移和顶点,处理并保存所有位移。 再次比显示的CM示例慢。
经过这次经历,我真的不理解CM读取广播如何工作以及如何在我的代码中正确“使用”它。 这段代码可能无法通过CM进行优化。
编辑2:
调整了一天后,我尝试了:
3)使用内存协调处理每个线程的更多顶点(8到64)(每个线程的增量相等于系统中的总线程数)-这比增量等于1的效果更好,但仍然没有加速。
4)替换此if语句
if (v.x * plane.x + v.y * plane.y + v.z * plane.z + plane.w > 0) {
++displacementSteps;
}
else {
--displacementSteps;
}
使用以下代码可以避免分支,但在一些情况下会产生“不可预测”的结果:
float dist = v.x * plane.x + v.y * plane.y + v.z * plane.z + plane.w;
int distInt = (int)(dist * (1 << 29)); // distance is in range (0 - 2), stretch it to int range
int sign = 1 | (distInt >> (sizeof(int) * CHAR_BIT - 1)); // compute sign without using ifs
displacementSteps += sign;
不幸的是,使用if语句慢了很多(约30%),因此if语句并没有像我想象的那样邪恶。
编辑3:
我得出结论,这个问题可能无法通过使用常量内存来改善,以下是我的结果*:
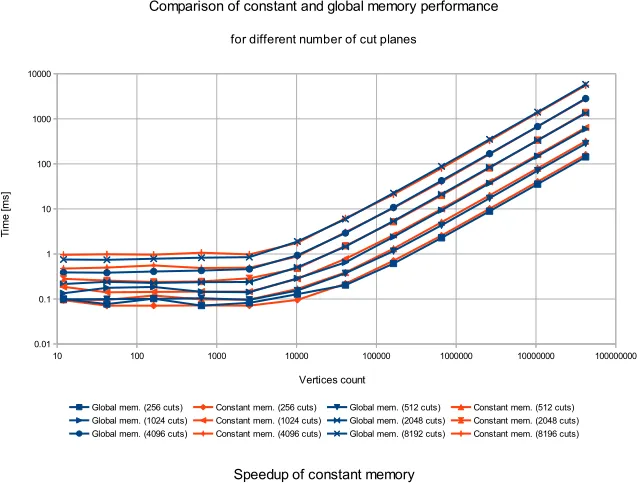
*时间报告是从15个独立测量中得出的中位数。当常量内存不足以保存所有平面(4096和8192)时,会多次调用内核。
__syncthreads()有不同的用途。当您想要同步块级线程时,例如在使用共享内存时,可以使用它。对于这种情况是不相关的。 - KiaMorot