有一些任务需要从文件中读取数据并进行处理,最后将结果写入文件。这些任务需要基于依赖关系进行调度。此外,任务可以并行运行,因此需要优化算法以使依赖任务串行运行,并尽可能多地并行运行。
例如:
另一种方式是先运行1,然后同时运行2、3和4。
还有一种方式是串行运行1和3,同时并行运行2和4。
你有什么想法吗?
例如:
- A -> B
- A -> C
- B -> D
- E -> F
另一种方式是先运行1,然后同时运行2、3和4。
还有一种方式是串行运行1和3,同时并行运行2和4。
你有什么想法吗?
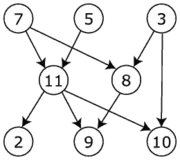
A,B,...是什么?在并行运行1和2是否意味着A被运行两次?这是不好的事情吗? - Jacob