我有大约100个采样率为48000的鸟类物种wav音频文件,我想要比较它们之间的相似性。我从音频文件开始,但我对处理图像更了解一些,所以我认为我的分析将在声谱图图像上进行。我有几个不同日期的鸟类样本。
以下是一些数据示例,以及(抱歉轴未标记; x是样本,y是线性频率乘以10,000 Hz的某种值):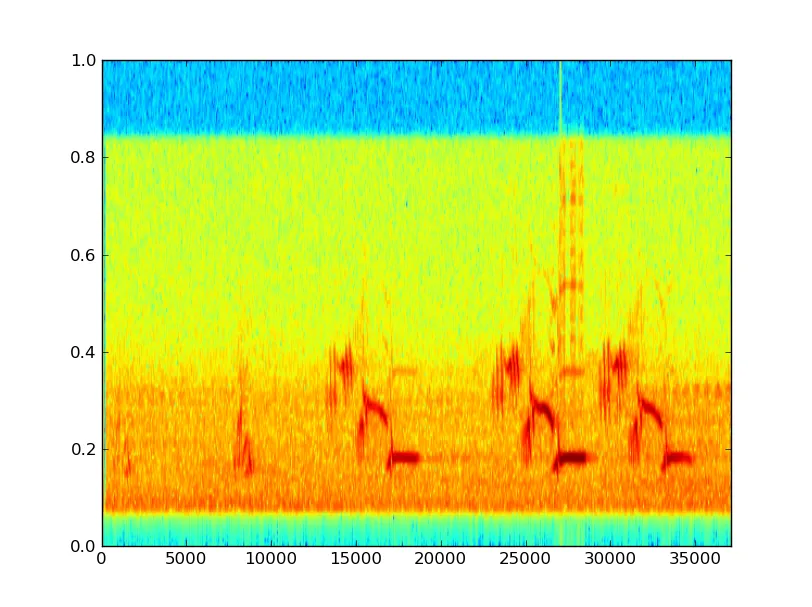 这些鸟鸣声显然发生在“单词”中,是歌曲的不同片段,这可能是我应该比较的层次; 相似单词之间的差异以及各种单词的频率和顺序。
这些鸟鸣声显然发生在“单词”中,是歌曲的不同片段,这可能是我应该比较的层次; 相似单词之间的差异以及各种单词的频率和顺序。
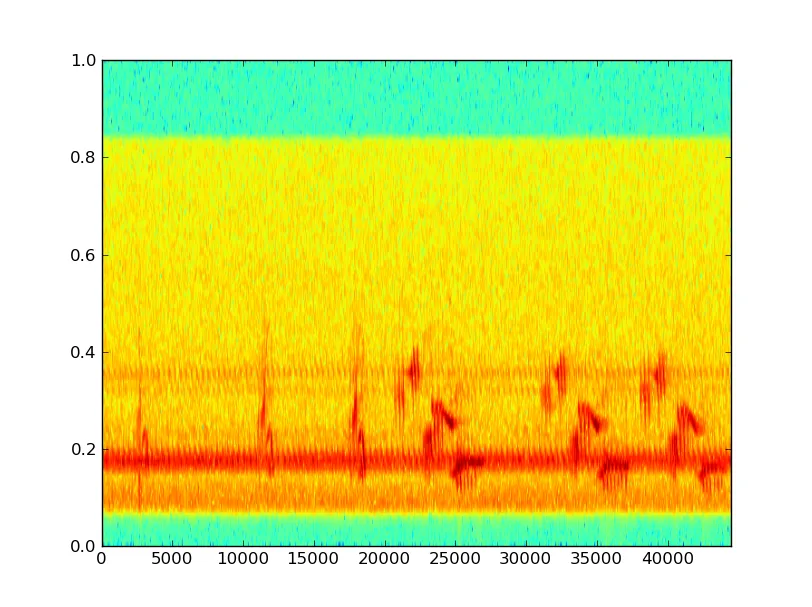 我想尝试去除蝉噪声-蝉鸣声具有相当一致的频率,并且倾向于相位匹配,因此这不应该太难。
我想尝试去除蝉噪声-蝉鸣声具有相当一致的频率,并且倾向于相位匹配,因此这不应该太难。
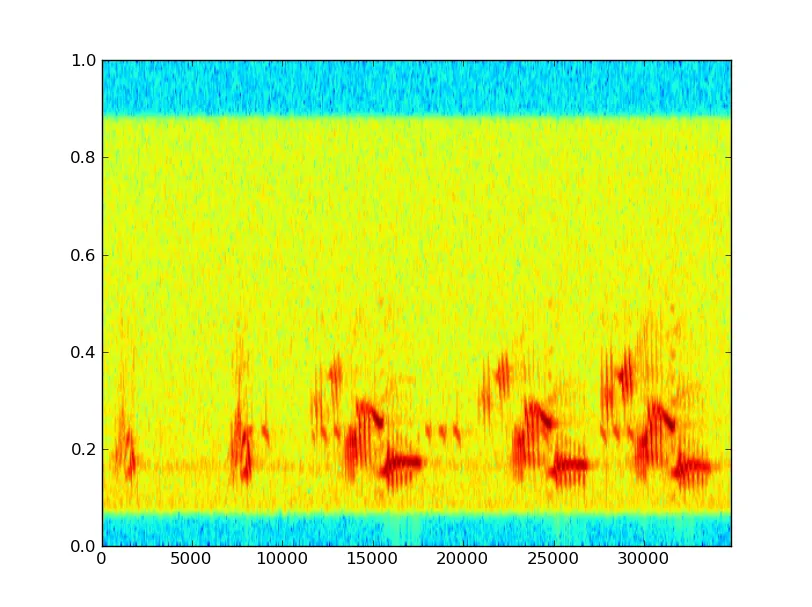 看起来阈值处理可能有用。
看起来阈值处理可能有用。
我被告知,大多数现有文献都使用基于歌曲特征的手动分类,例如Pandora Music Genome Project。我想要像Echo Nest一样使用自动分类。更新:很多人研究这个。
我的问题是,我应该使用什么工具进行此分析? 我需要:
以下是一些数据示例,以及(抱歉轴未标记; x是样本,y是线性频率乘以10,000 Hz的某种值):
这些鸟鸣声显然发生在“单词”中,是歌曲的不同片段,这可能是我应该比较的层次; 相似单词之间的差异以及各种单词的频率和顺序。
我想尝试去除蝉噪声-蝉鸣声具有相当一致的频率,并且倾向于相位匹配,因此这不应该太难。
看起来阈值处理可能有用。我被告知,大多数现有文献都使用基于歌曲特征的手动分类,例如Pandora Music Genome Project。我想要像Echo Nest一样使用自动分类。更新:很多人研究这个。
我的问题是,我应该使用什么工具进行此分析? 我需要:
- 过滤/阈值通用噪声并保留音乐
- 过滤掉像蝉一样的特定噪声
- 分割和分类鸟鸣中的短语、音节和/或音符
- 创建部分之间差异/相似性的度量;这将捕捉到不同鸟类之间的差异,同时最小化同一鸟类的不同叫声之间的差异
我选择的工具是numpy/scipy,但像openCV这样的工具可能也很有用?
编辑:在一些研究和Steve的帮助回答之后,更新了我的术语和方法。