我了解Redis的所有数据都是从内存中提供的,但当服务器重新启动时,它是否也可以跨越重启而持续存在,以便在服务器重新启动时从磁盘读入所有数据到内存中。或者它是否始终是一个空存储,仅用于在应用程序运行时存储数据,没有持久性?
Redis是否会持久化数据?
218
- Zuriar
1
2我不确定我是否正确地理解了你的问题。如果您没有这样做,您可以将快照保存到磁盘并从该文件中读取,否则在重新启动时,您的 Redis 数据库将为空。 - Sefa
7个回答
152
我建议您在http://redis.io/topics/persistence上了解更多相关内容。基本上,当您通过仅使用内存存储来提高性能时,您会失去可靠的持久性。想象一下,当您将数据插入到内存中时,但在它被持久化到磁盘之前断电了。这将导致数据丢失。
Redis支持所谓的“快照”。这意味着它会定期完全复制内存中的内容(例如每个整点)。如果在两次快照之间断电,您将会失去从最后一个快照到崩溃时间(不一定是停电)之间的数据。Redis在数据安全与性能之间进行折衷,就像大多数NoSQL数据库一样。
大多数NoSQL数据库都遵循多个节点之间的复制概念,以最小化此风险。 Redis被认为更像是一个快速缓存,而不是保证数据一致性的数据库。因此,它的用例通常与真实数据库不同:例如,您可以使用它来存储会话、性能计数器或其他内容,并获得无与伦比的性能,在崩溃的情况下没有真正的数据损失。但处理订单/购买历史记录等任务则被认为是传统数据库的工作。
- Manuel Arwed Schmidt
3
1如果您能添加默认的持久性行为,那将是非常好的。就像@Leonid Beschastny的回答一样。 - yeya
NoSql会取代Redis吗? - mercury
这在关系型数据库中是正确的,但使用AOF时,数据大多数情况下都不会因为电力损失或类似事件而丢失。 - ElementalStorm
75
Redis服务器会定期将其数据保存到硬盘,因此具有一定的持久性。
以下情况下会保存数据:
- 自动定期保存
- 手动调用
BGSAVE命令时 - 当Redis关闭时
但是,Redis中的数据并不是真正的持久性,因为:
- Redis进程崩溃会导致自上次保存以来所有更改丢失
BGSAVE操作只有在有足够空闲内存时才能执行(额外RAM的大小等于Redis数据库的大小)
N.B.:BGSAVE RAM 要求是一个真正的问题,因为Redis会在没有可运行的RAM之前继续工作,但它停止将数据保存到硬盘得更早(大约在RAM使用量的50%)。
更多信息请参见Redis Persistence。
- Leonid Beschastny
1
11自从这个答案被撰写以来,Redis引入了一种名为AOF的备份模式,它提供了更高的持久性,但也有一些缺点,比如更高的磁盘利用率和更慢的服务器启动速度。 - Leonid Beschastny
37
这是一个配置问题。您可以在Redis上没有、部分或完全持久化数据。最佳决策将由项目的技术和业务需求驱动。
根据Redis关于持久性的文档,您可以设置实例定期或在每次查询时将数据保存到磁盘中。 Redis提供了两种策略/方法AOF和RDB(阅读文档以查看其详细信息),您可以单独使用每种方法或一起使用。
如果您想要“类似SQL的持久性”,他们这样说:
一般建议如果您希望获得与PostgreSQL相当的数据安全度,应该同时使用这两种持久性方法。
- Adailson De Castro
15
一般而言是,但更完整的答案取决于你要存储的数据类型。通常,更完整的简短答案为:
- Redis不适合持久化存储,因为它主要注重性能。
- Redis实际上更适合于可靠的内存中存储/缓存当前状态数据,特别是为了通过提供用于跨多个客户端/服务器使用的数据的中央来源来实现可扩展性。
TL;DR
从官方文档得知:
- RDB持久化[默认]在指定的时间间隔内执行数据集的时间点快照。
- AOF持久化[需要显式配置]记录服务器接收到的每个写入操作,这些操作将在服务器启动时再次播放以重建原始数据集。
如果需要使用AOF持久化,Redis必须进行显式配置,这会导致性能损失以及日志的增长。对于相对可靠的有限数据流的持久化可能已经足够。
- Chris Halcrow
7
您可以选择不使用持久化。这样可以获得更好的性能,但是在Redis关闭时将失去所有数据。
Redis有两种持久化机制:RDB和AOF。RDB使用全局快照调度程序,而AOF将更新写入类似于MySQL的追加日志文件中。
您可以使用其中一种或两种机制。当Redis重新启动时,它会从读取RDB文件或AOF文件来构建数据。
- songxin
3
这个帖子中的所有答案都在谈论redis持久化数据的可能性:https://redis.io/topics/persistence(使用AOF + 每次写入(更改)之后)。
这是一个很好的链接,可以帮助您入门,但它绝对没有展示完整的情况。
Redis上真的可以/应该保留无法恢复的数据/状态吗?
Redis文档没有提及以下内容:
- 哪些Redis提供商支持此选项(AOF + 每次写入后):
- 几乎没有 - Redis云服务不提供此选项。您可能需要购买Redis-labs的本地版本来支持它。由于并非所有公司都愿意使用本地版本,因此他们将面临问题。
- 其他Redis提供商未指定是否支持此选项。AWS Cache,Aiven等
- AOF + 每次写入后 - 此选项较慢。您需要在生产硬件上自行测试以查看是否符合要求。
- Redis Enterprise提供此选项,请参见此链接https://redislabs.com/blog/your-cloud-cant-do-that-0-5m-ops-acid-1msec-latency/以查看一些基准测试结果:
在AWS上使用1个x1.16xlarge实例 - 他们无法达到低于2ms的延迟:
其中延迟是从请求的第一个字节到集群发送“写”响应的第一个字节返回给客户端的时间进行测量的
他们在更好的硬盘(Dell-EMC VMAX)上进行了额外的基准测试,结果为小于1ms的操作延迟(!!),并且从70K ops/sec(写入密集测试)增加到660K ops/sec(读取密集测试)。相当令人印象深刻!!!
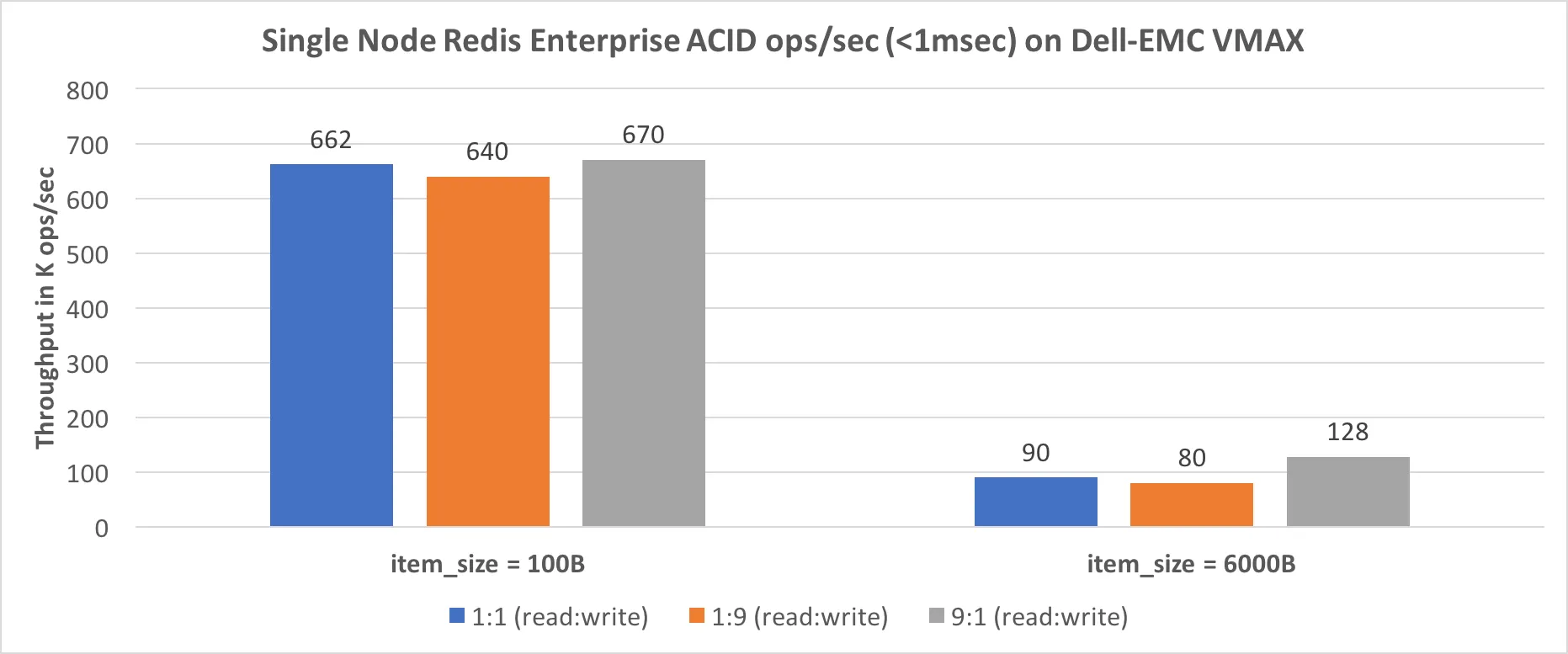
但是,要创建这种基础设施并随着时间的推移对其进行维护,需要一个(非常)熟练的DevOps。
- 有人可能会(错误地)认为,如果您拥有一组Redis节点(带有副本),那么现在您拥有了完全的持久性。这是虚假的声明:
- 所有DB(SQL,非SQL,Redis等)都有相同的问题-例如,在节点1上运行
set x 1,此更改(或任何更改)需要多长时间才能在所有其他节点中进行。因此,附加读取将接收相同的输出。嗯,这取决于很多因素和配置。 - 处理多个节点中键值不一致(任何DB类型)的值是一场噩梦。您可以从Redis作者(antirez)了解更多信息:http://antirez.com/news/66。以下是在Redis中存储状态的实际噩梦的简短示例(+解决方案-
WAIT命令以了解其他Redis节点接收到的最新更改量):
def save_payment(payment_id)
redis.rpush(payment_id,”in progress”) # Return false on exception
if redis.wait(3,1000) >= 3 then
redis.rpush(payment_id,”confirmed”) # Return false on exception
if redis.wait(3,1000) >= 3 then
return true
else
redis.rpush(payment_id,”cancelled”)
return false
end
else
return false
end
上面的例子并不足够,存在一个实际问题,即事先无法知道每个时刻有多少个节点(以及活动的节点)。
其他数据库也会遇到同样的问题。也许它们有更好的API,但问题仍然存在。
据我所知,很多应用程序甚至没有意识到这个问题。
总而言之,选择更多的数据库节点不是一键配置。它涉及到更多的内容。
总结这项研究,需要考虑以下几点:
- 你的团队有多少开发人员(避免此任务拖慢你)?
- 是否有经验丰富的运维工程师?
- 团队中分布式系统技能如何?
- 购买硬件的费用是否足够?
- 在解决方案上投入的时间是否足够?
- 还可能有更多其他因素...
- Stav Alfi
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接