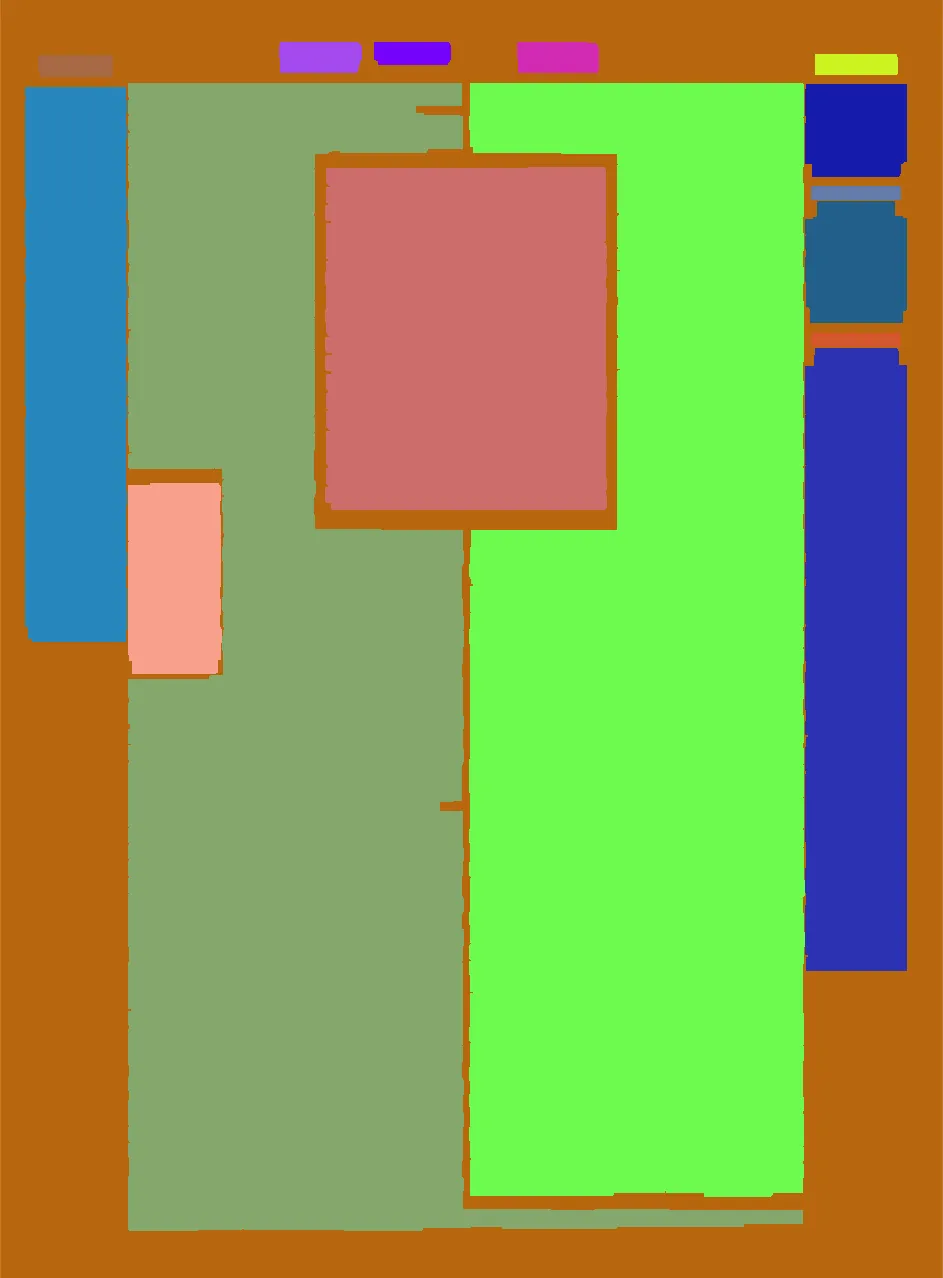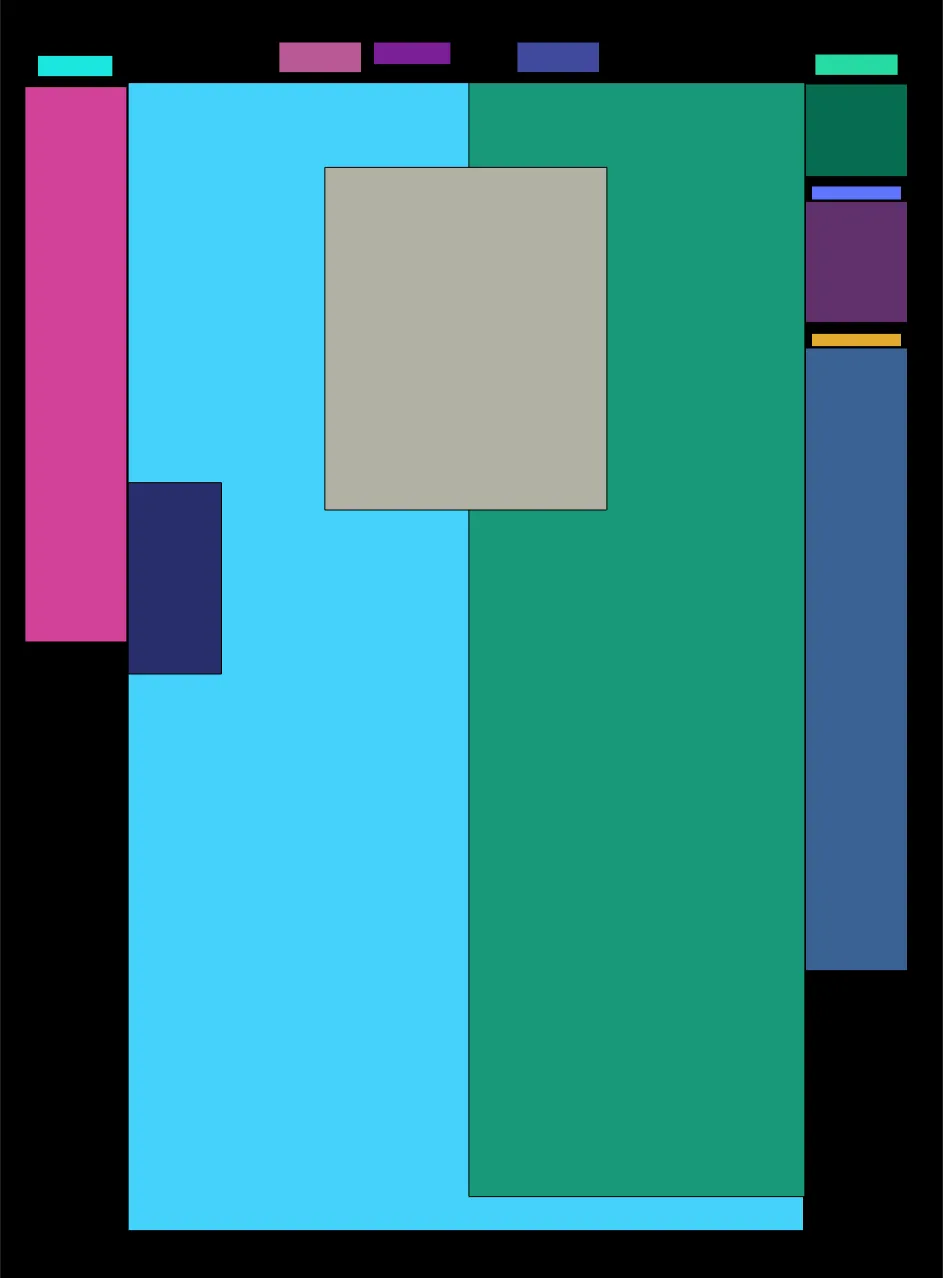我有一张像这样的塔木德页面:

 我想用
我想用
用眼睛做这件事真的很容易,根据穿过文本之间的白条纹,但我试图用
在下面的代码中,我尝试捕获所有的字母并将它们变成黑色矩形, 然后放大每个矩形以与相邻的矩形相遇, 这样整个文本区域将变成黑色,文本之间将有明显的白条纹。
我不知道该怎么做,也不知道这是否是一个好的方法。
我想用opencv找到文本区域,得到如下结果,每个文本都像这样单独出现:

用眼睛做这件事真的很容易,根据穿过文本之间的白条纹,但我试图用
opencv来做,但失败了。在下面的代码中,我尝试捕获所有的字母并将它们变成黑色矩形, 然后放大每个矩形以与相邻的矩形相遇, 这样整个文本区域将变成黑色,文本之间将有明显的白条纹。
我不知道该怎么做,也不知道这是否是一个好的方法。
public List<Rectangle> getRects(Mat grayImg)
{
BlobCounter blobCounter = new BlobCounter();
blobCounter.ObjectsOrder = ObjectsOrder.None;
blobCounter.ProcessImage(grayImg);
IEnumerable<Blob> blobs = blobCounter.GetObjectsInformation();
var blackBlobs = grayImg.Clone;
foreach (var b in blobs)
blackBlobs.Rectangle(b.Rectangle.ToCvRect, Scalar.Black, -1);
var widths = blobs.Select(X => X.Rectangle.Width).ToList;
widths.Sort();
var median = widths(widths.Count / (double)2);
Mat erodet = new Mat();
Cv2.Erode(grayImg, erodet, null, iterations: median);
using (Window win = new Window())
{
win.ShowImage(erodet);
win.WaitKey();
}
}
提前感谢,任何帮助都将不胜感激。
额外说明:
正如您在上一张图片中看到的那样,文本区域不是矩形的, 但可以将这些区域描述为不同大小的矩形集合,排列成一堆,一个接一个地放置。
请注意,当两个矩形属于同一文本时,不要将一个矩形排列在另一个矩形旁边,而只需将其一个接一个地放置在上面。
我想要实现的是这些矩形的集合,并知道每个矩形属于哪个文本。
答案可以使用任何编程语言,尤其是C++ Python 和 C#。