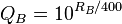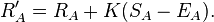我想通过制作一个游戏来对一组风景图片进行排名,让站点访问者评分,以找出人们最喜欢哪些图片。
有什么好的方法吗?
- 热门或不热门风格?即显示单个图像,要求用户给其排名1-10。在我的看法中,这允许我计算平均分数,我只需要确保在所有图像上获得投票的数量平均分布。实现相当简单。
- 选择A或B?即显示两个图像,要求用户选择更好的一个。这很吸引人,因为它没有数字排名,只是一个比较。但我该怎么实现呢?我的第一个想法是将其作为快速排序来完成,比较操作由人类提供,完成后,只需无限重复排序。
你会如何做呢?
如果你需要数字,我正在谈论的是拥有一百万张图片的网站,每天有20,000次访问。我想象可能只有一小部分人会玩这个游戏,为了方便起见,假设我每天可以生成2,000个人工排序操作!这是一个非营利性网站,好奇心旺盛的人可以通过我的个人资料找到它:)