我知道这可能是一个非常小众的问题,但有没有人有使用连续神经网络的经验?我特别想知道连续神经网络与通常用于离散神经网络的用途有何区别。
为了明确起见,我要澄清一下我所说的“连续神经网络”的含义,因为我认为它有不同的解释。我并不是指激活函数是连续的。相反,我暗示了将隐藏层中的神经元数量增加到无限数量的想法。
因此,为了明确起见,这是您典型的离散NN的架构:
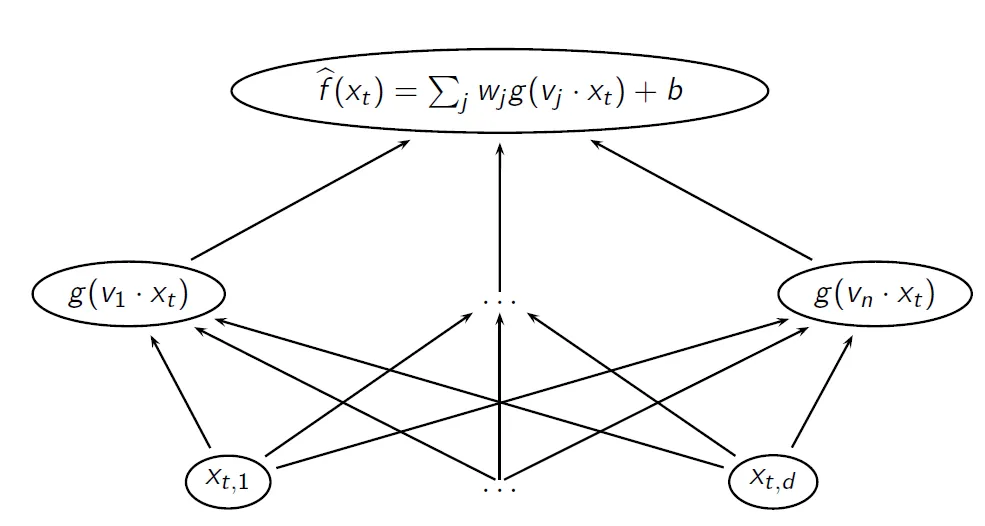
(来源:garamatt at sites.google.com)
{kind=link}
x是输入,g是隐藏层的激活函数,v是隐藏层的权重,w是输出层的权重,b是偏置,输出层具有线性激活(即无)。
离散NN和连续NN之间的区别如下图所示:
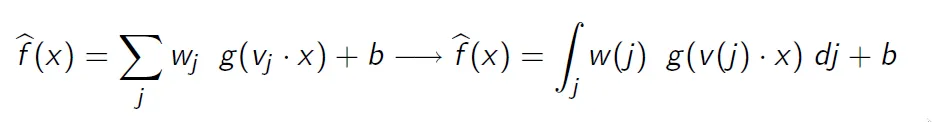
(来源:garamatt at sites.google.com)
{kind=link}
也就是说,您让隐藏神经元数量变为无限大,以便您的最终输出是一个积分。在实践中,这意味着您不是计算确定性总和,而是必须使用数值积分来近似相应的积分。
显然,神经网络的一个普遍误解是太多的隐藏神经元会导致过拟合。
我的问题特指离散和连续神经网络的定义,我想知道是否有人有使用后者的经验以及他们用它做了什么。
更多关于这个主题的描述可以在这里找到:http://www.iro.umontreal.ca/~lisa/seminaires/18-04-2006.pdf