我是一位有用的助手,可以翻译文本。
我是编译器构建领域的新手,我想知道直接编码和表驱动词法分析器之间的区别是什么?
如果可能,请使用简单的源代码示例。
谢谢。
编辑:
在Engineering a Compiler这本书中,作者将词法分析器分为三种类型:表驱动、直接编码和手工编码。
我是编译器构建领域的新手,我想知道直接编码和表驱动词法分析器之间的区别是什么?
如果可能,请使用简单的源代码示例。
谢谢。
编辑:
在Engineering a Compiler这本书中,作者将词法分析器分为三种类型:表驱动、直接编码和手工编码。
ab*a相对应的有限状态自动机(故意不最小化):
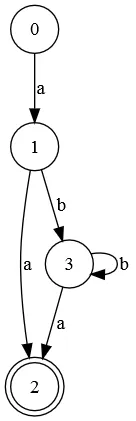
#define REJECT -1
/* This table encodes the transitions for a given state and character. */
const int transitions[][] = {
/* In state 0, if we see an a then go to state 1 (the 1).
* Otherwise, reject input.
*/
{ /*a*/ 1, /*b*/ REJECT },
{ /*a*/ 2, /*b*/ 3 },
{ /*a*/ -1, /*b*/ -1 }, /* Could put anything here. */
{ /*a*/ 2, /*b*/ 3 }
};
/* This table determines, for each state, whether it is an accepting state. */
const int accept[] = { 0, 0, 1, 0 };
int scan(void) {
char ch;
int state = 0;
while (!accept[state]) {
ch = getchar() - 'a'; /* Adjust so that a => 0, b => 1. */
if (transitions[state][ch] == REJECT) {
fprintf(stderr, "invalid token!\n");
return 0; /* Fail. */
} else {
state = transitions[state][ch];
}
}
return 1; /* Success! */
}
enum token {
ERROR,
LPAREN,
RPAREN,
IDENT,
NUMBER
};
enum token scan(void) {
/* Consume all leading whitespace. */
char ch = first_nonblank();
if (ch == '(') return LPAREN;
else if (ch == ')') return RPAREN;
else if (isalpha(ch)) return ident();
else if (isdigit(ch)) return number();
else {
printf("invalid token!\n");
return ERROR;
}
}
char first_nonblank(void) {
char ch;
do {
ch = getchar();
} while (isspace(ch));
return ch;
}
enum token ident(void) {
char ch;
do {
ch = getchar();
} while (isalpha(ch));
ungetc(ch, stdin); /* Put back the first non-alphabetic character. */
return IDENT;
}
enum token number(void) {
char ch;
do {
ch = getchar();
} while (isdigit(ch));
ungetc(ch, stdin); /* Put back the first non-digit. */
return NUMBER;
}
像表驱动词法分析器示例一样,这个示例也不完整。首先,它需要某种缓冲区来存储作为标记的字符,例如IDENT和NUMBER。其次,它不能很好地处理EOF。但希望您能理解其要点。
编辑:根据编译器工程中的定义,直接编码的词法分析器基本上是两者的混合体。不使用表格,而是使用代码标签来表示状态。让我们看看在使用与之前相同的DFA时它会是什么样子。
int scan(void) {
char ch;
state0:
ch = getchar();
if (ch == 'a') goto state1;
else { error(); return 0; }
state1:
ch = getchar();
if (ch == 'a') goto state2;
else if (ch == 'b') goto state3;
else { error(); return 0; }
state2:
return 1; /* Accept! */
state3:
ch = getchar();
if (ch == 'a') goto state2;
else if (ch == 'b') goto state3; /* Loop. */
else { error(); return 0; }
}