有几种选项可用于处理大量套接字连接的程序(例如Web服务、P2P系统等)。
因此,我的问题是哪种方法被人们发现最有效,或者是否有其他方法比上面列出的任何一种更好?对实际生活中的图表、白皮书和/或网络可用的写作的参考将不胜感激。
- 为每个套接字生成一个单独的线程来处理I/O。
- 使用select系统调用将I/O多路复用到单个线程中。
- 使用poll系统调用将I/O多路复用(替换select)。
- 使用epoll系统调用,避免反复通过用户/系统边界发送套接字fd。
- 生成若干个I/O线程,每个线程使用poll API多路复用相对较小的一组总连接数。
- 与#5类似,但使用epoll API为每个独立的I/O线程创建一个单独的epoll对象。
因此,我的问题是哪种方法被人们发现最有效,或者是否有其他方法比上面列出的任何一种更好?对实际生活中的图表、白皮书和/或网络可用的写作的参考将不胜感激。
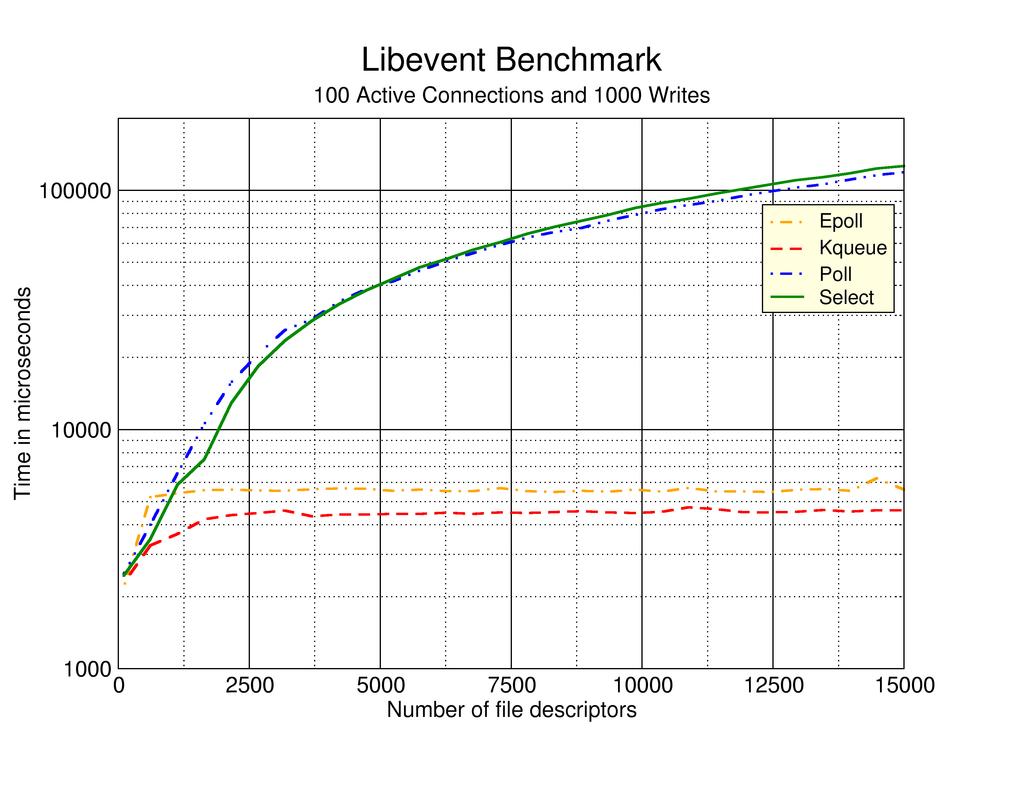 。
。