我希望在调试器中看到剪贴板符号:(U+1F4CB)。
我理解这两个码点。
其中:
- \ud83d 是 ߓ
- \u8dccb 是
我希望对其进行详细格式化,以便在Unicode的调试提示中查看。
我的当前详细格式化程序(首选项->Java-Debug->详细格式化程序)如下:
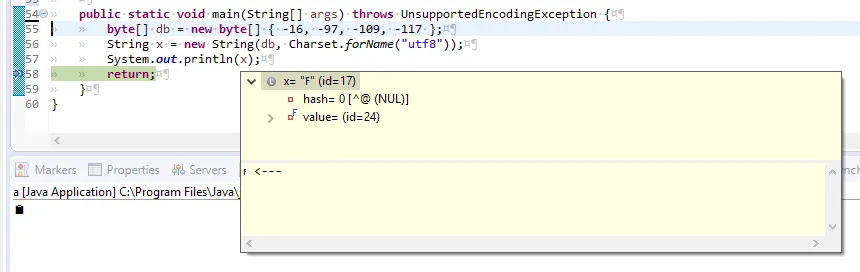
new String(this.getBytes("utf8"), java.nio.charset.Charset.forName("utf8")).concat(" <---")
以上代码仅在详细视图中添加了<---,没有其他效果。
问题1:
我需要哪种格式化程序才能正确显示黄色提示框中的字符?
源代码
import java.nio.charset.Charset;
public class Test {
public static void main(String[] args) {
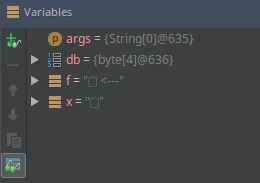
byte[] db = new byte[] { -16, -97, -109, -117 };
String x = new String(db, Charset.forName("utf8"));
System.out.println(x);
return;
}
}
String实现内部使用的任何编码方式编码的,通常是UTF-16,但这并不重要,因为软件接口是以Unicode定义的。正如所解释的那样,将其转换为UTF-8,然后再转换回String完全过时了,因为结果字符串与原始字符串相同。这证明了,“utf-8字符”这种说法是多么荒谬。 - HolgerString实例,并且 UTF-8 编码与 Eclipse 的 Detail Formatter 没有任何关系。中间转换为 UTF-8 只会分散注意力。你因此给了我负评,并发表了一些关于“UTF-8 字符”是一种东西以及对我的句子“在 Detail Formatter 中没有任何事情可以做”进行错误引用的抱怨,所以你可以自由地解释一下你的问题中实际有价值的内容。 - HolgerString、JVM的调试接口以及Java软件Eclipse为基础。理论上,它应该已经可以工作,在实践中,它适用于BMP中的所有代码点,即0 - \uFFFF范围内。它不能处理SMP字符,即\uFFFF以上的字符,这是一个错误。由于传输协议良好,因此无需选择编码。这是一个错误。 - Holger