我正在尝试构建一个在.Net环境中使用的正则表达式,以从webvtt文件中提取信息。 我想提取时间码信息和下一行(可能是字幕或其他内容)对应的信息。但我遇到的问题是,下一行的信息有时只有一行,有时却跨越多行。
第二个(或第三个,根据上面所述):
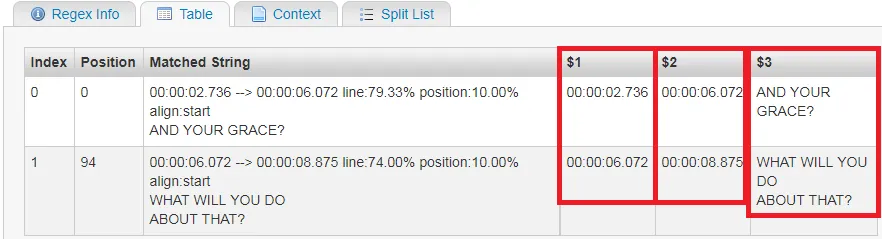
00:00:02.736 --> 00:00:06.072 line:79.33% position:10.00% align:start
AND YOUR GRACE?
00:00:06.072 --> 00:00:08.875 line:74.00% position:10.00% align:start
WHAT WILL YOU DO
ABOUT THAT?
我需要确保获取所有内容,而不会无意中进入下一个组的开头。
我尝试过这个:
\n(\d{2}:\d{2}:\d{2}.\d{3})(.|\n)*(?<!\d{2}:\d{2}:\d{2}.\d{3})
这个想法是获取第一个 timecode 及其后的所有内容,但在下一个第一个 timecode 出现时停止,但它捕获整个文件。
我也尝试过:
(?<!WEBVTT)(\d{2}:\d{2}:\d{2}.\d{3}).*?(\d{2}:\d{2}:\d{2}.\d{3}).*\n([^\n]+\n)*[^\n]+
我意识到在开头使用负向先行断言是多余的。这里我试图将时间码放入单独的组中,忽略该行的其余部分,然后捕获从新行开始的所有内容,但这会跳过字幕文本并且不能涵盖多个行。
我似乎遇到的问题是要么捕获太多行,要么不够。
有没有办法告诉正则表达式匹配某些内容(例如第一个时间码)和其后的所有内容,然后在命中第一次匹配时重新开始?
我相信这一定是可能的,但我是使用正则表达式的新手,所以我觉得很难。如果必须分解为多个操作才能获得所需的结果,我也不介意。
所以我想要的是:
第一组可以是:
00:00:02.736
或者
00:00:02.736 --> 00:00:06.072
第二个(或第三个,根据上面所述):
AND YOUR GRACE?
然后:
00:00:06.072 --> 00:00:08.875
接着是:
WHAT WILL YOU DO
ABOUT THAT?
etc
var res = str.Split(new[] {"\r\n\r\n"}, StringSplitOptions.RemoveEmptyEntries)如何?如果你无法访问代码,则尝试使用(?sm)^(\d{2}:\d{2}:\d{2}\.\d+) +--> +(\d{2}:\d{2}:\d{2}\.\d+)((?:(?!\r?\n\r?\n).)*)。 - Wiktor Stribiżew