使用最新版本的Tensor Flow在Windows上,我试图使一切尽可能高效。然而,即使从源代码编译,我仍然无法弄清如何启用SSE和AVX指令。
默认流程: https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/contrib/cmake 没有提到如何做到这一点。
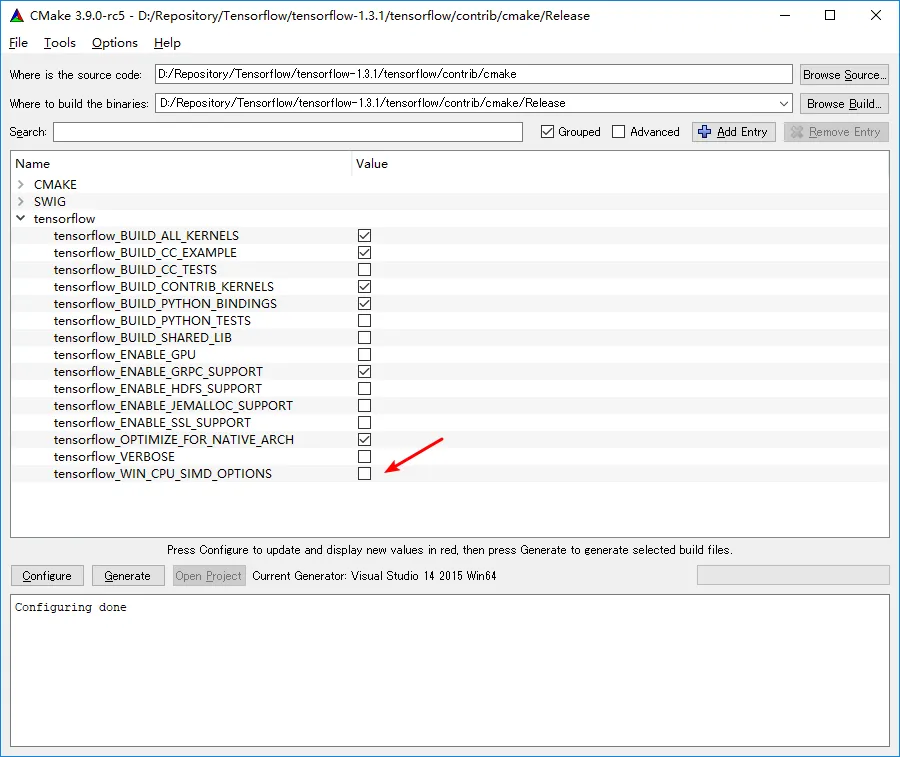
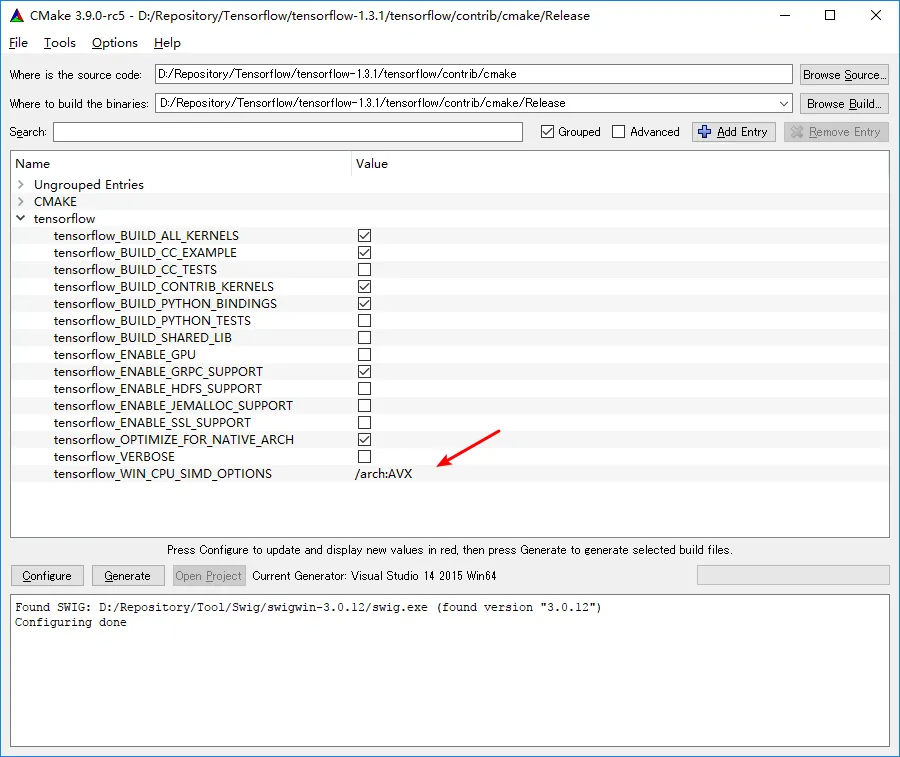
我唯一找到的参考资料是使用Google的Bazel: How to compile Tensorflow with SSE4.2 and AVX instructions? 有人知道使用MSBuild轻松打开这些高级指令的方法吗?我听说它们可以提高至少3倍的速度。
为了帮助那些寻找类似解决方案的人,我现在收到的警告看起来像这样: https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/contrib/cmake
默认流程: https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/contrib/cmake 没有提到如何做到这一点。
我唯一找到的参考资料是使用Google的Bazel: How to compile Tensorflow with SSE4.2 and AVX instructions? 有人知道使用MSBuild轻松打开这些高级指令的方法吗?我听说它们可以提高至少3倍的速度。
为了帮助那些寻找类似解决方案的人,我现在收到的警告看起来像这样: https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/contrib/cmake
我正在使用Windows 10专业版64位平台,Visual Studio 2015社区版,Anaconda Python 3.6,以及cmake版本3.6.3(Tensor Flow不支持更高版本)。
{kind=link}
{kind=link}
{kind=link}