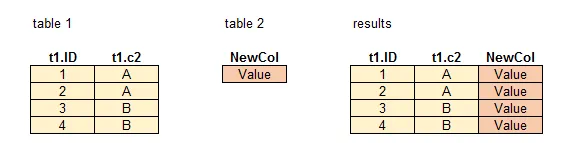
经过试验,令人惊讶的是,在处理大型表格时,将点表左联接速度要比将单个值分配给列要快得多。所谓点表是指1x1的表格(即一行一列)。
方法1。 在说“将单个值分配”时,我指的是以下方法(速度较慢):
SELECT A.*, 'Value' as NewColumn,
FROM Table1 A
方法二。 通过 左连接 点表,我指的是这个(更快):
WITH B AS (SELECT 'Value' as 'NewColumn')
SELECT * Table1 A
LEFT JOIN B
ON A.ID <> B.NewColumn
现在是我的问题的核心。有人能建议我如何摆脱整个ON子句吗:
ON A.ID <> B.NewColumn?
检查连接条件似乎是浪费时间,因为表A的键必须不等于表B的键。如果t1.ID的值与'Value'相同,则它会将行从结果中排除。删除该条件或者将<>更改为=符号,似乎可以进一步节省连接的性能空间。
2015年2月23日更新
悬赏问题面向性能专家。我在问题和答案中提到的哪种方法最快。
方法1 简单赋值,
方法2 左连接一个点表格,
方法3 交叉连接一个点表格(感谢Gordon Linoff的答案)
方法4 在奖励期间可能建议的任何其他方法。
根据我对3种方法查询执行时间的经验测量 - 第二种采用LEFT JOIN的方法是最快的。然后是CROSS JOIN方法,最后是简单的赋值。令人惊讶。需要拥有所罗门之剑的性能专家来确认或否认它。
ON 1=1是否更简单呢?一些非常快速的测试表明这样稍微更有效率。顺便说一句,在我所有的测试中,CROSS JOIN 都是最好的选择... - gvee