我知道乌龟和兔子相遇的地方标志着一个循环的存在,但是当我们将乌龟移动到链表的开头并保持兔子在相遇的地方,然后两个指针都每次向前移动一步时,它们如何会聚到循环的起点呢?
如何在循环链表中找到环的起点节点?
201
- Passionate programmer
2
另一个解释:https://marcin-chwedczuk.github.io/find-cycle-start-in-singly-linked-list - csharpfolk
我想知道如果使用Brent算法,是否有人能够轻松找到循环的起点。 - gnasher729
23个回答
4
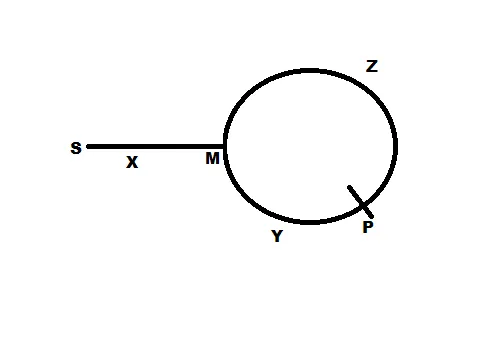
- user9639921
4
已经有很多关于这个问题的答案了,但是我曾经为此设计过一张图表,对我来说更具直观性。也许它能帮助其他人。
对我来说,主要的“啊哈”时刻是:
将T(乌龟)分成T1(循环前)和T2(循环中)。
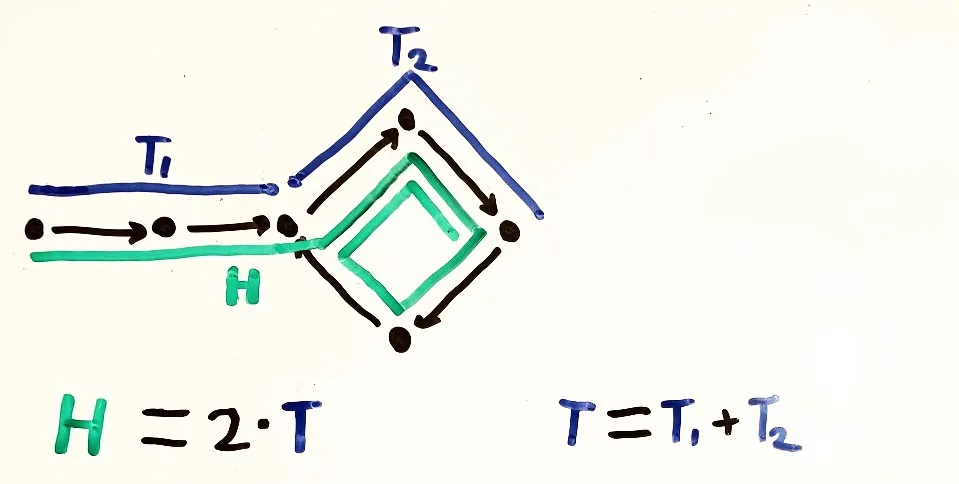
从重叠的可视部分减去T,剩下的(H-T=H')等于T。
- 剩下的数学计算非常简单。
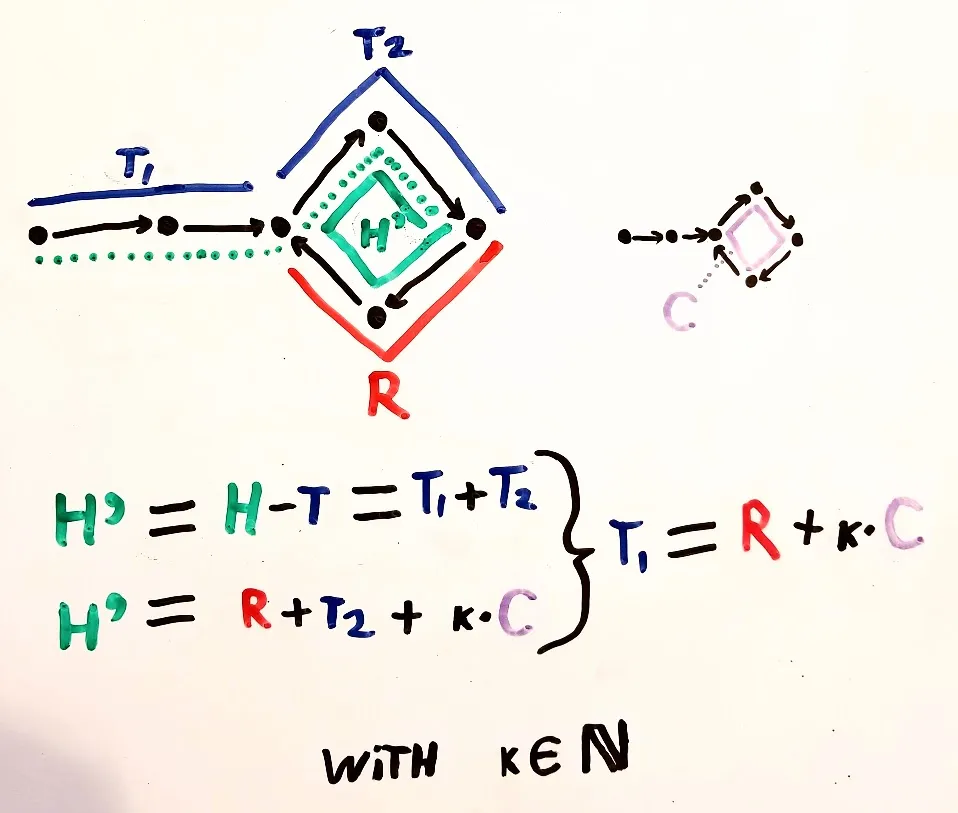
- mhelvens
3
-在循环之前有k个步骤。我们不知道k是多少,也不需要找出来。我们可以抽象地只使用k。
--k步之后
----- T位于循环开始处
----- H进入了循环的k步(他总共走了2k步,因此在循环中走了k步)
** 现在它们相距循环大小-k
(请注意,k == K == mod(loopsize,k)--例如,如果一个节点在5个节点循环中走了2步,那么它也在7、12或392步内,因此循环的大小与k有关系不会影响结果。
由于它们以每个单位时间1步的速度相遇,因为其中一个移动的速度是另一个的两倍,所以它们将在循环大小-k处相遇。
这意味着需要k个节点才能到达循环的开头,因此从头到循环起点的距离和碰撞到循环起点的距离相同。
现在在第一次碰撞后,将T移回头部。如果以每个单位时间1步的速度移动,则T和H将在循环开始处相遇。 (对于两者都需要k步)
这意味着算法是:
- 从头开始移动T = t.next和H.next.next,直到它们碰撞(T == H)(存在循环)
//处理k = 0或T和H在循环头相遇的情况,通过计算循环的长度
--通过使用计数器将T或H移动到循环周围来计算循环的长度
--将指针T2移动到列表的头部
--移动指针循环步数
--将另一个指针H2移动到头部
--同时移动T2和H2,直到它们在循环的开始处相遇
就是这样!
- Droid Teahouse
3
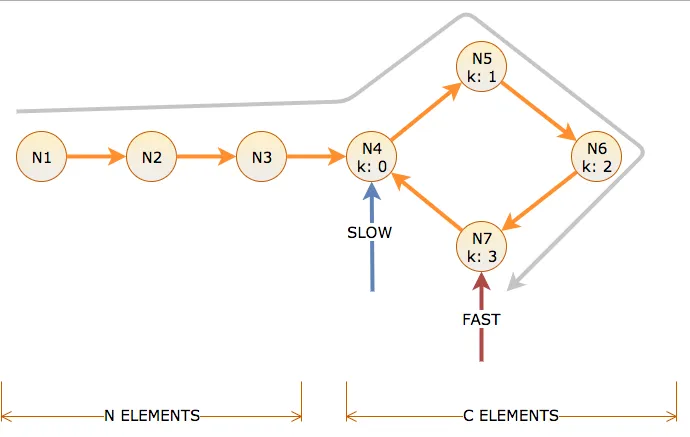
将指针跟随的链接数量称为距离,将算法移动慢指针一个链接和快指针两个链接的迭代次数称为时间。在循环长度为C之前有N个节点,用循环偏移量k = 0到C-1进行标记。
为了到达循环的起点,慢指针需要N次时间和距离。这意味着快指针在循环中需要N距离(N到达那里,N旋转)。因此,在时间N时,慢指针位于循环偏移量k = 0处,快指针位于循环偏移量k = N mod C处。
如果N mod C为零,则慢指针和快指针现在匹配,并且在时间N和循环位置k = 0处找到循环。
如果N mod C不为零,则快指针现在必须赶上慢指针,此时慢指针在循环中落后于C - (N mod C)距离。
由于快指针每次移动2个单位,慢指针每次移动1个单位,所以在每次迭代中距离缩小1个单位,这需要额外的时间与快慢指针在时间N时的距离相同,即C-(N mod C)。由于慢指针从偏移量0开始移动,这也是它们相遇的偏移量。
因此,如果N mod C为零,则第一阶段在循环开始的N次迭代后停止。否则,在N+C-(N mod C)次迭代后,第一阶段将在循环的偏移量C-(N mod C)处停止。
// C++ pseudocode, end() is one after last element.
int t = 0;
T *fast = begin();
T *slow = begin();
if (fast == end()) return [N=0,C=0];
for (;;) {
t += 1;
fast = next(fast);
if (fast == end()) return [N=(2*t-1),C=0];
fast = next(fast);
if (fast == end()) return [N=(2*t),C=0];
slow = next(slow);
if (*fast == *slow) break;
}
好的,所以第二阶段:慢指针需要再走N步才能到达循环点,此时快指针(现在每个时间步骤移动1个位置)位于(C-(N mod C)+N) mod C = 0处。因此,在第二阶段结束后,它们会在循环的起始点相遇。
int N = 0;
slow = begin();
for (;;) {
if (*fast == *slow) break;
fast = next(fast);
slow = next(slow);
N += 1;
}
为了完整性,第三阶段通过再次遍历循环来计算循环长度:
int C = 0;
for (;;) {
fast = next(fast);
C += 1;
if (fast == slow) break;
}
- Warren MacEvoy
2
模拟算法的Google文档链接:https://docs.google.com/spreadsheets/d/1LXEBc3EqrkQkUycx5oA_yqEZRbjBMIvrW5rt9oxb-IY/edit?usp=sharing - Warren MacEvoy
1请注意,如果N <= C,则迭代在C次迭代后停止。无论如何,它必须在少于N + C步骤内停止,并且不太可能在循环开始时停止。 - Warren MacEvoy
2
通过以上分析,如果您是一个喜欢通过实例学习的人,我尝试写了一个简短的分析和示例来帮助解释其他人试图解释的数学问题。我们开始吧!
分析:
如果我们有两个指针,一个比另一个更快,并一起移动它们,它们最终会再次相遇,以指示循环或null以指示没有循环。
要找到循环的起点,请执行以下操作...
m是从头到循环开始的距离;d是循环中节点的数量;p1是较慢指针的速度;p2是较快指针的速度,例如2表示每次穿过两个节点。观察以下迭代:
m = 0, d = 10:
p1 = 1: 0 1 2 3 4 5 6 7 8 9 10 // 0 would the start of the cycle
p2 = 2: 0 2 4 6 8 10 12 14 16 18 20
m = 1, d = 10:
p1 = 1: -1 0 1 2 3 4 5 6 7 8 9
p2 = 2: -1 1 3 5 7 9 11 13 15 17 19
m = 2, d = 10:
p1 = 1: -2 -1 0 1 2 3 4 5 6 7 8
p2 = 2: -2 0 2 4 6 8 10 12 14 16 18
从上面的示例数据中,我们可以轻松发现,无论何时快指针和慢指针相遇,它们距离循环的起点都是m步。为了解决这个问题,将快指针放回到头部,并将其速度设置为慢指针的速度。当它们再次相遇时,该节点就是循环的起点。
- Steve
2
使用图表可以更好地解释问题,我尝试在不使用方程式的情况下解释问题。
- 如果我们让兔子和乌龟在一个圆圈里跑步,兔子比乌龟快两倍,那么当兔子跑完一圈时,乌龟会在半圈的位置。当兔子跑了两圈时,乌龟已经跑了一圈,他们相遇了。这适用于所有速度,例如,如果兔子跑三倍,那么兔子跑一圈等于乌龟的1/3,所以当兔子跑了三圈时,乌龟已经跑了一圈,他们相遇了。
- 现在,如果我们让它们在循环前m步开始跑步,那么意味着更快的兔子在循环中提前开始奔跑。因此,如果乌龟到达循环的起点,兔子就在循环前m步的位置,当它们相遇时,距离循环起点还有m步。
- shiva kumar
1
假设,
N[0] is the node of start of the loop,
m is the number of steps from beginning to N[0].
我们有两个指针 A 和 B,A 以 1x 的速度运行,B 以 2x 的速度运行,两者都从开头开始。
当 A 到达 N[0] 时,B 应该已经在 N[m] 处。 (注意:A 使用 m 步到达 N[0],B 应该再向前走 m 步)
然后,A 再运行 k 步以与 B 碰撞, 即 A 在 N[k] 处,B 在 N[m+2k] 处 (注意:B 应该从 N[m] 开始运行 2k 步)
A 在 N[k] 和 B 在 N[m+2k] 处碰撞,这意味着 k=m+2k,因此 k = -m
因此,要从 N[k] 循环回到 N[0],我们需要再走 m 步。
简单地说,我们只需要在找到碰撞节点后再运行 m 步。我们可以有一个指针从开头运行,另一个指针从碰撞节点运行,它们将在 m 步后在 N[0] 处相遇。
因此,伪代码如下:
1) A increase 1 step per loop
2) B increase 2 steps per loop
3) if A & B are the same node, cycle found, then go to 5
4) repeat from 1
5) A reset to head
6) A increase 1 step per loop
7) B increase 1 step per loop
8) if A & B are the same node, start of the cycle found
9) repeat from 6
- phdfong - Kenneth Fong
1
我不认为当它们相遇时就是起点。但是,如果另一个指针(F)在会合点之前,那么该指针将位于循环的末尾而不是循环的开头,而从列表开头开始的指针(S)将最终停留在循环的开头。例如:
1->2->3->4->5->6->7->8->9->10->11->12->13->14->15->16->17->18->19->20->21->22->23->24->8
Meet at :16
Start at :8
public Node meetNodeInLoop(){
Node fast=head;
Node slow=head;
fast=fast.next.next;
slow=slow.next;
while(fast!=slow){
fast=fast.next;
fast=fast.next;
if(fast==slow) break;
slow=slow.next;
}
return fast;
}
public Node startOfLoop(Node meet){
Node slow=head;
Node fast=meet;
while(slow!=fast){
fast=fast.next;
if(slow==fast.next) break;
slow=slow.next;
}
return slow;
}
- MrSham
1
在花费两个小时阅读所有答案后,我在LeetCode上找到了这条评论。可以说,它拯救了我的夜晚。
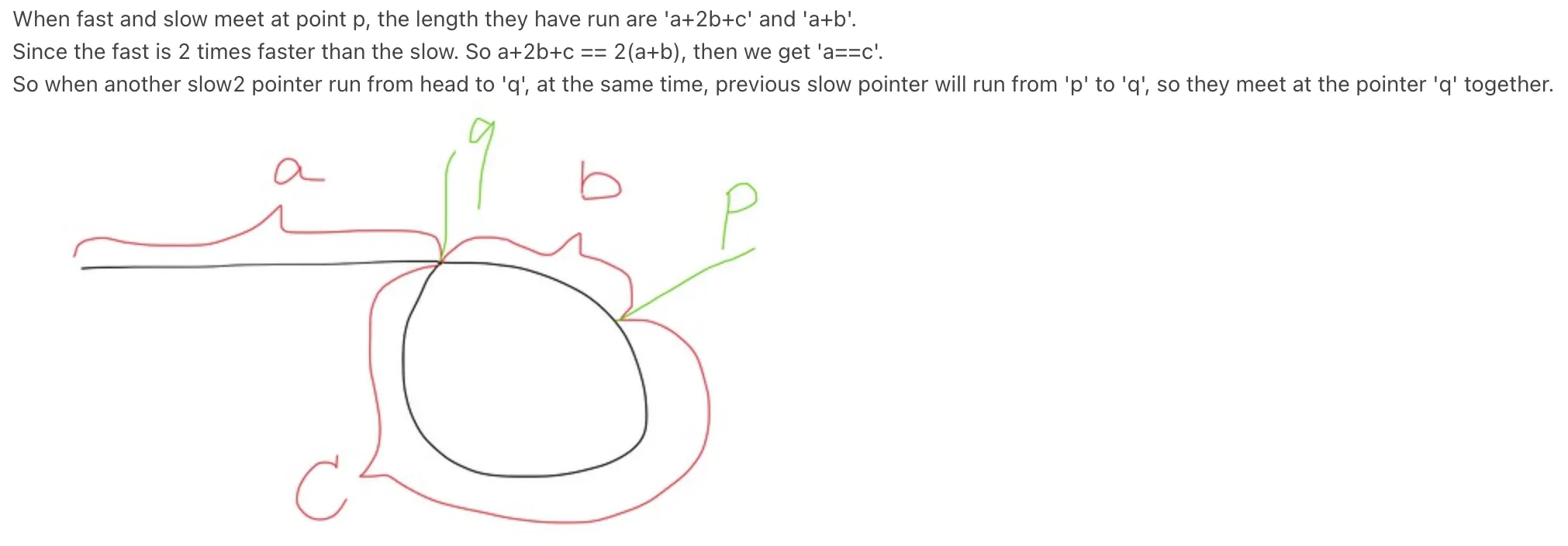
- Pavithran Ravichandiran
0
我看到大多数答案都对这个问题给出了数学解释:“如何将乌龟移动到链表开头,同时保持兔子在相遇点,然后一步一步地移动两者,使它们在循环的起始点相遇?”
下面的方法也像 Floyd 算法一样在幕后执行循环检测,但其原理简单,代价是 O(n) 的内存。
我想添加一个更简单的方法/原理来找到循环的起始点。由于这种方法没有在任何地方提到过,我在这里进行了测试:https://leetcode.com/problems/linked-list-cycle-ii/,并且通过了所有的测试用例。
让我们考虑我们已经获得了 LinkedList 的头引用。
public ListNode detectCycle(ListNode head) {
// Consider a fast pointer which hops two nodes at once.
// Consider a slow pointer which hops one node at once.
// If the linked list contains a cycle,
// these two pointers would meet at some point when they are looping around the list.
// Caution: This point of intersection need not be the beginning of the cycle.
ListNode fast = null;
ListNode slow = null;
if (head != null) {
if (head.next != null) {
fast = head.next.next;
slow = head;
} else {
return null;
}
}
while (fast != null && fast.next != null) {
// Why do we need collection here? Explained below
Set<ListNode> collection = new HashSet<>();
if (fast == slow) {
// Once the cycle is detected,
we are sure that there is beginning to the cycle.
// In order to find this beginning,
// 1. move slow pointer to head and keep fast pointer at
the meeting point.
// 2. now while moving slow and fast pointers through a
single hop, store the slow reference in a collection.
// 3. Every time you hop the fast pointer, check the fast
pointer reference exits in that collection.
// Rationale: After we moved slow pointer to the head,
we know that slow pointer is coming behind the fast
pointer, since collection is storing all nodes from the
start using slow pointer, there is only one case we get
that fast pointer exists in the collection when slow
pointer started storing the nodes which are part of the
cycle. Because slow pointer can never go ahead of fast
pointer since fast pointer already has an head-start, at
the same time, the first occurence will always be of the
starting point of the cycle because slow pointer can't
go ahead of fast pointer to store other nodes in the
cycle. So, the moment we first find fast pointer in that
collection means, that is the starting point of the
cycle.
slow = head;
collection.add(slow);
while (!collection.contains(fast)) {
slow = slow.next;
collection.add(slow);
fast = fast.next;
}
return fast;
}
fast = fast.next.next;
slow = slow.next;
}
return null;
}
- manikanta nvsr
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接