我正在制作一个C语言的静态分析器。 我用ANTLR完成了词法分析器和语法分析器,并生成了Java代码。
ANTLR是否通过options {output=AST;}自动为我们构建AST?还是我必须自己构建树?如果是前者,那么如何输出AST上的节点?
我目前认为,在AST上的节点将用于生成SSA,然后进行数据流分析以制作静态分析器。我走在正确的道路上吗?
我正在制作一个C语言的静态分析器。 我用ANTLR完成了词法分析器和语法分析器,并生成了Java代码。
ANTLR是否通过options {output=AST;}自动为我们构建AST?还是我必须自己构建树?如果是前者,那么如何输出AST上的节点?
我目前认为,在AST上的节点将用于生成SSA,然后进行数据流分析以制作静态分析器。我走在正确的道路上吗?
Raphael写道:
antlr是否通过选项{output=AST;}自动为我们构建抽象语法树?还是我必须手动构造树?如果它是,那么如何将AST上的节点输出?
不,解析器不知道您想要哪些解析规则作为根节点和叶节点,因此您需要更多地工作,而不仅仅是在语法中放置options { output=AST; }。
例如,当使用从以下语法生成的解析器解析源代码"true && (false || true && (true || false))"时:
grammar ASTDemo;
options {
output=AST;
}
parse
: orExp
;
orExp
: andExp ('||' andExp)*
;
andExp
: atom ('&&' atom)*
;
atom
: 'true'
| 'false'
| '(' orExp ')'
;
// ignore white space characters
Space
: (' ' | '\t' | '\r' | '\n') {$channel=HIDDEN;}
;

(即仅为标记的平面、一维列表)
您需要告诉ANTLR语法中哪些标记成为根、叶子或简单地留在树外。
创建AST有两种方法:
foo:A B C D -> ^(D A B);,其中foo是匹配标记A B C D的解析器规则。因此,->后面的所有内容都是实际的重写规则。正如您所看到的,标记C未在重写规则中使用,这意味着它从AST中省略了。直接放置在^(之后的标记将成为树的根;!和^之后使用树运算符,其中^将使标记成为根,!将从树中删除标记。对于foo:A B C D -> ^(D A B);的等效方式是foo:A B C!D ^;foo:A B C D -> ^(D A B);和foo:A B C!D ^;都将生成以下AST:
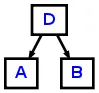
grammar ASTDemo;
options {
output=AST;
}
parse
: orExp
;
orExp
: andExp ('||'^ andExp)* // Make `||` root
;
andExp
: atom ('&&'^ atom)* // Make `&&` root
;
atom
: 'true'
| 'false'
| '(' orExp ')' -> orExp // Just a single token, no need to do `^(...)`,
// we're removing the parenthesis. Note that
// `'('! orExp ')'!` will do exactly the same.
;
// ignore white space characters
Space
: (' ' | '\t' | '\r' | '\n') {$channel=HIDDEN;}
;
这将从源代码 "true && (false || true && (true || false))" 创建以下AST:
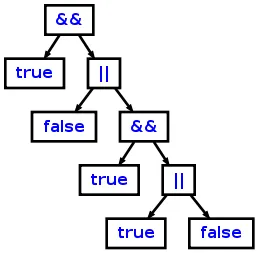
相关的ANTLR维基链接:
Raphael写道:
我目前正在考虑AST上的节点将用于制作SSA,然后进行数据流分析以制作静态分析器。我走在正确的道路上吗?
我从未做过这样的事情,但在我看来,你首先需要从源代码中获得AST,所以是的,我想你走在了正确的道路上! :)
下面是如何使用生成的词法分析器和语法分析器:
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
String src = "true && (false || true && (true || false))";
ASTDemoLexer lexer = new ASTDemoLexer(new ANTLRStringStream(src));
ASTDemoParser parser = new ASTDemoParser(new CommonTokenStream(lexer));
CommonTree tree = (CommonTree)parser.parse().getTree();
DOTTreeGenerator gen = new DOTTreeGenerator();
StringTemplate st = gen.toDOT(tree);
System.out.println(st);
}
}
CommonTree tree是你想要的)。 - Bart Kiers