对于我们构建的应用程序,我们使用了一个简单的统计模型来进行单词预测(类似于Google自动完成),以引导搜索。
它使用从大量相关文本文档中收集的ngram序列。通过考虑前N-1个单词,它建议按概率降序显示五个最可能的“下一个单词”,使用Katz后退模型。
我们希望将此扩展为预测短语(多个单词)而不是单个单词。但是,在预测短语时,我们希望不显示其前缀。
例如,考虑输入the cat。
在这种情况下,我们想预测像the cat in the hat这样的内容,但不是the cat in和the cat in the。
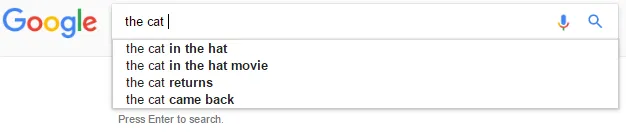
假设:
我们无法访问过去的搜索统计数据
我们没有带标签的文本数据(例如,我们不知道词性)
通常如何进行这些多单词预测? 我们尝试了较长短语的乘法和加法加权,但是我们的权重是任意的,并且过度拟合于我们的测试。