考虑一个字符向量
我想对这些元素进行抽样,数量为
这可以稍微改进一下,通过最初从
In the second figure above, if 010 was the first pick, all nodes at black nodes are still (currently) valid, assuming n <= 4. For example, if n==4 and we sampled node 1 next (and so our picks now included 01 and 1), we would subsequently disallow node 00 (due to rule 2 above) but could still pick 000 and 001, giving us our 4-element sample. If n==5, on the other hand, node 1 would be disallowed at this stage.
pool,其元素是最多具有max_len位的(前导零填充的)二进制数字。max_len <- 4
pool <- unlist(lapply(seq_len(max_len), function(x)
do.call(paste0, expand.grid(rep(list(c('0', '1')), x)))))
pool
## [1] "0" "1" "00" "10" "01" "11" "000" "100" "010" "110"
## [11] "001" "101" "011" "111" "0000" "1000" "0100" "1100" "0010" "1010"
## [21] "0110" "1110" "0001" "1001" "0101" "1101" "0011" "1011" "0111" "1111"
我想对这些元素进行抽样,数量为
n,但有一个限制条件,不能选择任何已经被选中元素的前缀(例如,如果我们选择了1101,则不能再选择以1、11和110开头的元素,而如果我们选择1,则不能再选择以1开头的元素,如10、11、100等)。
以下是我的while尝试,但当n很大时(或接近2^max_len)速度会很慢。
set.seed(1)
n <- 10
chosen <- sample(pool, n)
while(any(rowSums(outer(paste0('^', chosen), chosen, Vectorize(grepl))) > 1)) {
prefixes <- rowSums(outer(paste0('^', chosen), chosen, Vectorize(grepl))) > 1
pool <- pool[rowSums(Vectorize(grepl, 'pattern')(
paste0('^', chosen[!prefixes]), pool)) == 0]
chosen <- c(chosen[!prefixes], sample(pool, sum(prefixes)))
}
chosen
## [1] "0100" "0101" "0001" "0011" "1000" "111" "0000" "0110" "1100" "0111"
这可以稍微改进一下,通过最初从
pool中移除那些包含将意味着在pool中剩余的元素不足以取得大小为n的总样本的元素来实现。例如,当max_len = 4且n > 9时,我们可以立即从pool中删除0和1,因为通过包括其中任何一个,最大样本将是9(要么是0和以1开头的八个4字符元素,要么是1和以0开头的八个4字符元素)。
基于这种逻辑,我们可以在取初始样本之前像这样省略pool中的元素:
pool <- pool[
nchar(pool) > tail(which(n > (2^max_len - rev(2^(0:max_len))[-1] + 1)), 1)]
有人能想到更好的方法吗?我觉得我可能忽略了更简单的方法。
编辑
为了澄清我的意图,我将把池子描绘成一组分支,其中交叉点和末端是节点(pool的元素)。假设在下面的图中黄色节点(即010)被绘制出来。现在,整个红色“分支”,由节点0、01和010组成,将从池子中移除。这就是我所说的禁止采样已经在我们的样本中“前缀”节点(以及那些已经被我们的样本中的节点“前缀”的节点)的含义。
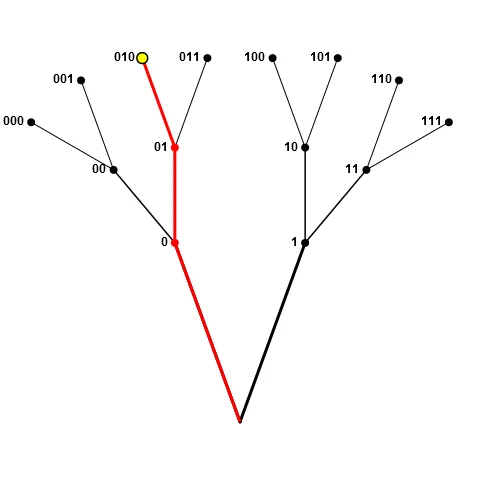
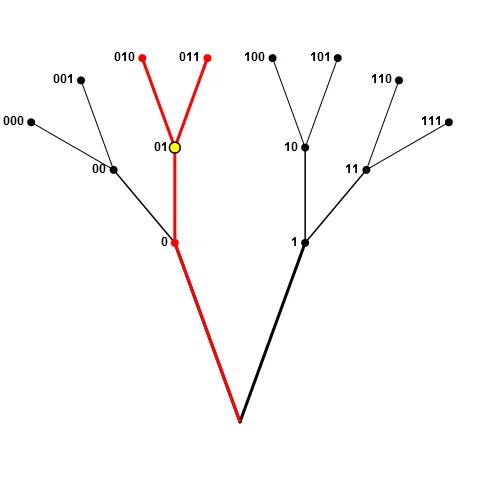
In the second figure above, if 010 was the first pick, all nodes at black nodes are still (currently) valid, assuming n <= 4. For example, if n==4 and we sampled node 1 next (and so our picks now included 01 and 1), we would subsequently disallow node 00 (due to rule 2 above) but could still pick 000 and 001, giving us our 4-element sample. If n==5, on the other hand, node 1 would be disallowed at this stage.
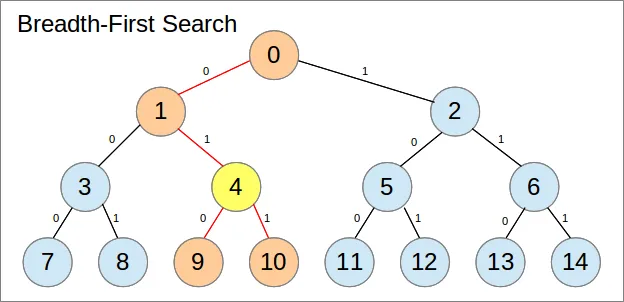 作为一个数组,它占用的内存较少(没有更多指针),所使用的内存是连续的(对于缓存很好),并且可以完全放在堆栈上而不是堆(假设您的语言给您选择)。当然,这里有一些条件,特别是数组的大小。我稍后会回到这个问题。
作为一个数组,它占用的内存较少(没有更多指针),所使用的内存是连续的(对于缓存很好),并且可以完全放在堆栈上而不是堆(假设您的语言给您选择)。当然,这里有一些条件,特别是数组的大小。我稍后会回到这个问题。