class和struct的性能。我预计总结值类型将始终更快。但对于短数组来说并非如此。有人能解释一下吗?代码:
internal class ReferenceType
{
public int Value;
}
internal struct ValueType
{
public int Value;
}
internal struct ExtendedValueType
{
public int Value;
private double _otherData; // this field is here just to make the object bigger
}
我有三个数组:
private ReferenceType[] _referenceTypeData;
private ValueType[] _valueTypeData;
private ExtendedValueType[] _extendedValueTypeData;
我使用相同的随机值初始化它。
然后是一个基准测试方法:
[Benchmark]
public int ReferenceTypeSum()
{
var sum = 0;
for (var i = 0; i < Size; i++)
{
sum += _referenceTypeData[i].Value;
}
return sum;
}
Size是一个基准参数。
另外两种基准方法(ValueTypeSum和ExtendedValueTypeSum)相同,只是在_valueTypeData或_extendedValueTypeData上进行求和。完整的基准代码。
基准结果:
DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64位 RyuJIT-v4.7.3190.0
Method | Size | Mean | Error | StdDev | Ratio | RatioSD |
--------------------- |----- |----------:|----------:|----------:|------:|--------:|
ReferenceTypeSum | 100 | 75.76 ns | 1.2682 ns | 1.1863 ns | 1.00 | 0.00 |
ValueTypeSum | 100 | 79.83 ns | 0.3866 ns | 0.3616 ns | 1.05 | 0.02 |
ExtendedValueTypeSum | 100 | 78.70 ns | 0.8791 ns | 0.8223 ns | 1.04 | 0.01 |
| | | | | | |
ReferenceTypeSum | 500 | 354.78 ns | 3.9368 ns | 3.6825 ns | 1.00 | 0.00 |
ValueTypeSum | 500 | 367.08 ns | 5.2446 ns | 4.9058 ns | 1.03 | 0.01 |
ExtendedValueTypeSum | 500 | 346.18 ns | 2.1114 ns | 1.9750 ns | 0.98 | 0.01 |
| | | | | | |
ReferenceTypeSum | 1000 | 697.81 ns | 6.8859 ns | 6.1042 ns | 1.00 | 0.00 |
ValueTypeSum | 1000 | 720.64 ns | 5.5592 ns | 5.2001 ns | 1.03 | 0.01 |
ExtendedValueTypeSum | 1000 | 699.12 ns | 9.6796 ns | 9.0543 ns | 1.00 | 0.02 |
核心 : .NET Core 2.1.4 (CoreCLR 4.6.26814.03, CoreFX 4.6.26814.02), 64位 RyuJIT
Method | Size | Mean | Error | StdDev | Ratio | RatioSD |
--------------------- |----- |----------:|----------:|----------:|------:|--------:|
ReferenceTypeSum | 100 | 76.22 ns | 0.5232 ns | 0.4894 ns | 1.00 | 0.00 |
ValueTypeSum | 100 | 80.69 ns | 0.9277 ns | 0.8678 ns | 1.06 | 0.01 |
ExtendedValueTypeSum | 100 | 78.88 ns | 1.5693 ns | 1.4679 ns | 1.03 | 0.02 |
| | | | | | |
ReferenceTypeSum | 500 | 354.30 ns | 2.8682 ns | 2.5426 ns | 1.00 | 0.00 |
ValueTypeSum | 500 | 372.72 ns | 4.2829 ns | 4.0063 ns | 1.05 | 0.01 |
ExtendedValueTypeSum | 500 | 357.50 ns | 7.0070 ns | 6.5543 ns | 1.01 | 0.02 |
| | | | | | |
ReferenceTypeSum | 1000 | 696.75 ns | 4.7454 ns | 4.4388 ns | 1.00 | 0.00 |
ValueTypeSum | 1000 | 697.95 ns | 2.2462 ns | 2.1011 ns | 1.00 | 0.01 |
ExtendedValueTypeSum | 1000 | 687.75 ns | 2.3861 ns | 1.9925 ns | 0.99 | 0.01 |
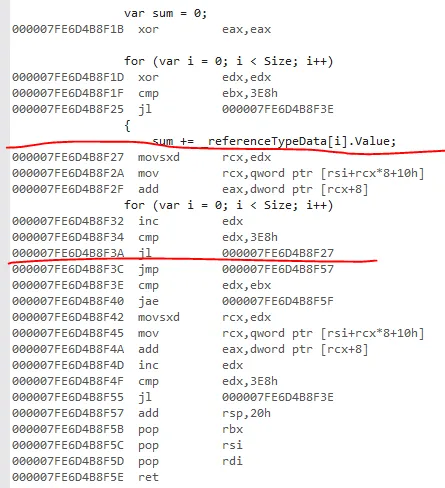
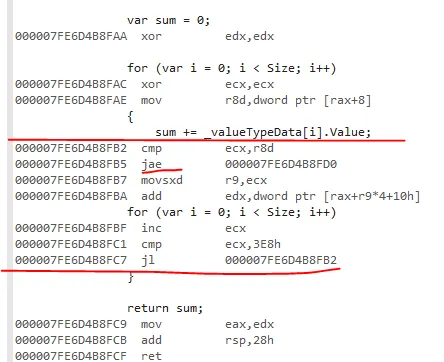
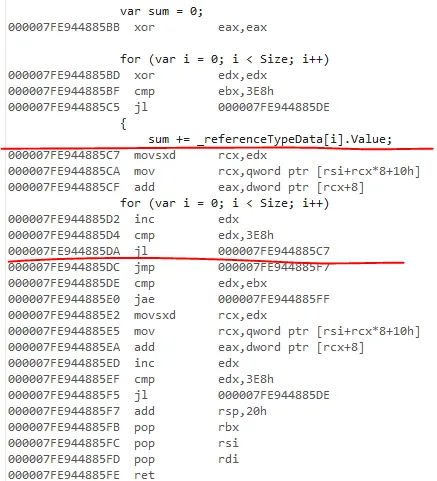
我已经使用BranchMispredictions和CacheMisses硬件计数器运行了基准测试,但是没有缓存未命中或分支错误预测。我还检查了发布的IL代码,并且基准测试方法仅通过加载引用或值类型变量的指令而不同。
对于更大的数组大小,对值类型数组求和总是更快的(例如,因为值类型占用的内存较少),但我不明白为什么对于较短的数组来说速度会变慢。我在这里错过了什么?为什么使struct更大(参见ExtendedValueType)会使求和稍微快一点?
---- 更新 ----
受@usr评论的启发,我使用LegacyJit重新运行了基准测试。我还添加了内存诊断器,受@Silver Shroud启发(是的,没有堆分配)。
工作=LegacyJitX64 Jit=LegacyJit 平台=X64 运行时=Clr
Method | Size | Mean | Error | StdDev | Ratio | RatioSD | Gen 0/1k Op | Gen 1/1k Op | Gen 2/1k Op | Allocated Memory/Op |
--------------------- |----- |-----------:|-----------:|-----------:|------:|--------:|------------:|------------:|------------:|--------------------:|
ReferenceTypeSum | 100 | 110.1 ns | 0.6836 ns | 0.6060 ns | 1.00 | 0.00 | - | - | - | - |
ValueTypeSum | 100 | 109.5 ns | 0.4320 ns | 0.4041 ns | 0.99 | 0.00 | - | - | - | - |
ExtendedValueTypeSum | 100 | 109.5 ns | 0.5438 ns | 0.4820 ns | 0.99 | 0.00 | - | - | - | - |
| | | | | | | | | | |
ReferenceTypeSum | 500 | 517.8 ns | 10.1271 ns | 10.8359 ns | 1.00 | 0.00 | - | - | - | - |
ValueTypeSum | 500 | 511.9 ns | 7.8204 ns | 7.3152 ns | 0.99 | 0.03 | - | - | - | - |
ExtendedValueTypeSum | 500 | 534.7 ns | 3.0168 ns | 2.8219 ns | 1.03 | 0.02 | - | - | - | - |
| | | | | | | | | | |
ReferenceTypeSum | 1000 | 1,058.3 ns | 8.8829 ns | 8.3091 ns | 1.00 | 0.00 | - | - | - | - |
ValueTypeSum | 1000 | 1,048.4 ns | 8.6803 ns | 8.1196 ns | 0.99 | 0.01 | - | - | - | - |
ExtendedValueTypeSum | 1000 | 1,057.5 ns | 5.9456 ns | 5.5615 ns | 1.00 | 0.01 | - | - | - | - |
使用传统的JIT编译器,结果符合预期,但比以前的结果慢!这表明RyuJit进行了一些神奇的性能改进,对引用类型效果更好。
---- 更新2 ----
感谢大家的回答!我学到了很多!
以下是另一个基准测试的结果。我正在比较最初进行基准测试的方法,根据@usr和@xoofx的建议进行了优化的方法:
[Benchmark]
public int ReferenceTypeOptimizedSum()
{
var sum = 0;
var array = _referenceTypeData;
for (var i = 0; i < array.Length; i++)
{
sum += array[i].Value;
}
return sum;
}
并且根据@AndreyAkinshin的建议,使用展开版本和未展开版本,加上以上优化:
[Benchmark]
public int ReferenceTypeUnrolledSum()
{
var sum = 0;
var array = _referenceTypeData;
for (var i = 0; i < array.Length; i += 16)
{
sum += array[i].Value;
sum += array[i + 1].Value;
sum += array[i + 2].Value;
sum += array[i + 3].Value;
sum += array[i + 4].Value;
sum += array[i + 5].Value;
sum += array[i + 6].Value;
sum += array[i + 7].Value;
sum += array[i + 8].Value;
sum += array[i + 9].Value;
sum += array[i + 10].Value;
sum += array[i + 11].Value;
sum += array[i + 12].Value;
sum += array[i + 13].Value;
sum += array[i + 14].Value;
sum += array[i + 15].Value;
}
return sum;
}
基准测试结果:
BenchmarkDotNet=v0.11.3, 操作系统=Windows 10.0.17134.345 (1803/April2018Update/Redstone4) Intel Core i5-6400 CPU 2.70GHz (Skylake), 1个CPU,4个逻辑核心和4个物理核心 频率=2648439 Hz,分辨率=377.5809 ns,计时器=TSC
DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000),64位 RyuJIT-v4.7.3190.0
Method | Size | Mean | Error | StdDev | Ratio | RatioSD |
------------------------------ |----- |---------:|----------:|----------:|------:|--------:|
ReferenceTypeSum | 512 | 344.8 ns | 3.6473 ns | 3.4117 ns | 1.00 | 0.00 |
ValueTypeSum | 512 | 361.2 ns | 3.8004 ns | 3.3690 ns | 1.05 | 0.02 |
ExtendedValueTypeSum | 512 | 347.2 ns | 5.9686 ns | 5.5831 ns | 1.01 | 0.02 |
ReferenceTypeOptimizedSum | 512 | 254.5 ns | 2.4427 ns | 2.2849 ns | 0.74 | 0.01 |
ValueTypeOptimizedSum | 512 | 353.0 ns | 1.9201 ns | 1.7960 ns | 1.02 | 0.01 |
ExtendedValueTypeOptimizedSum | 512 | 280.3 ns | 1.2423 ns | 1.0374 ns | 0.81 | 0.01 |
ReferenceTypeUnrolledSum | 512 | 213.2 ns | 1.2483 ns | 1.1676 ns | 0.62 | 0.01 |
ValueTypeUnrolledSum | 512 | 201.3 ns | 0.6720 ns | 0.6286 ns | 0.58 | 0.01 |
ExtendedValueTypeUnrolledSum | 512 | 223.6 ns | 1.0210 ns | 0.9550 ns | 0.65 | 0.01 |