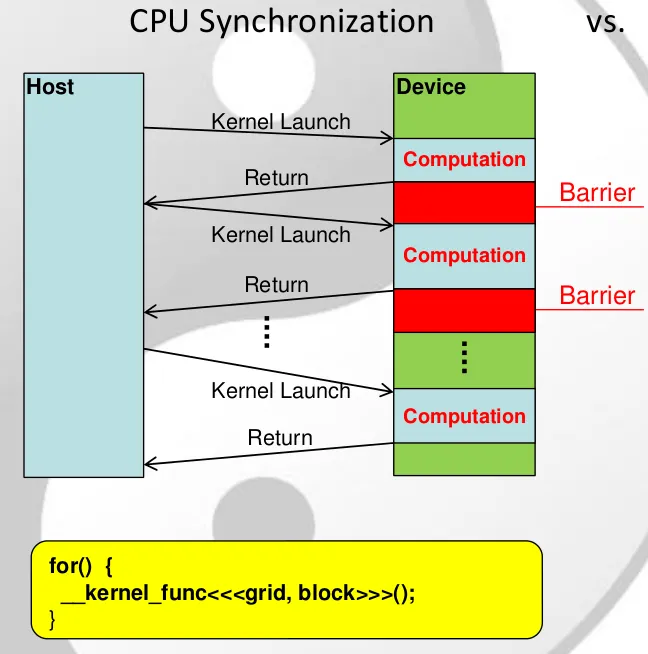
__syncthreads()函数是否同步网格中的所有线程,还是只同步当前warp或块中的线程?
此外,当特定块中的线程在内核中遇到以下行时:
此外,当特定块中的线程在内核中遇到以下行时:
__shared__ float srdMem[128];
他们只会在每个块中声明这个空间一次吗?
显然,它们都是异步操作的,因此如果块22中的线程23是第一个到达此行的线程,然后块22中的线程69是最后一个到达此行的线程,则线程69将知道它已经被声明了吗?