当客户端通过RPC触发cordapp并等待结果时,会出现这样的情况。
rpcConnection.proxy
.startFlow(::ImportAssetFlow, importDto)
.returnValue
.get(importTimeout /* 30000 ms */, TimeUnit.MILLISECONDS)
流触发器正确执行并返回响应,但在处理完流程后响应速度慢是个问题。在FlowLogic.call()代码块的末尾,响应应通过Artemis消息返回给客户端。12秒后,结果通过Corda future返回给客户端。
在客户端上,可以使用RPCClientProxyHandler的调试级别日志检查进程工作方式:
2020-01-08 12:12:45.982 DEBUG [,,,] 78798 --- [global-threads)] n.c.c.r.internal.RPCClientProxyHandler : Got message from RPC server RpcReply(id=fc317c4a-3de4-4936-b4c3-768b8b727245, timestamp: 2020-01-08T10:12:44.237Z, entityType: Invocation, result=Success(FlowHandleImpl(id=[16566124-f7d2-41cf-b3a4-f86846073632], returnValue=net.corda.core.internal.concurrent.CordaFutureImpl@58f8aa01)), deduplicationIdentity=e3f6d696-dea4-45b0-95b8-f9c0fe363a9f)
2020-01-08 12:12:45.986 DEBUG [,,,] 78798 --- [global-threads)] n.c.c.r.internal.RPCClientProxyHandler : Got message from RPC server Observation(id=b3f0b064-6d82-4900-85e6-e70b7d00926a, timestamp: 2020-01-08T10:11:26.411Z, entityType: Invocation, content=[rx.Notification@b461fac0 OnNext Added(stateMachineInfo=StateMachineInfo([16566124-f7d2-41cf-b3a4-f86846073632], ***.workflow.asset.flow.ImportAssetFlow))], deduplicationIdentity=e3f6d696-dea4-45b0-95b8-f9c0fe363a9f)
2020-01-08 12:12:45.987 DEBUG [,,,] 78798 --- [global-threads)] n.c.c.r.internal.RPCClientProxyHandler : Got message from RPC server Observation(id=12887a04-f22c-422d-b684-c679f137d66b, timestamp: 2020-01-08T10:12:45.979Z, entityType: Invocation, content=[rx.Notification@4c59250 OnNext Starting], deduplicationIdentity=e3f6d696-dea4-45b0-95b8-f9c0fe363a9f)
2020-01-08 12:12:58.603 DEBUG [,,,] 78798 --- [global-threads)] n.c.c.r.internal.RPCClientProxyHandler : Got message from RPC server Observation(id=b83c15ca-9047-4958-a106-65165e5abfbd, timestamp: 2020-01-08T10:12:45.975Z, entityType: Invocation, content=[rx.Notification@e03cfa2d OnNext [B@2dceac3d], deduplicationIdentity=e3f6d696-dea4-45b0-95b8-f9c0fe363a9f)
2020-01-08 12:12:58.605 DEBUG [,,,] 78798 --- [global-threads)] n.c.c.r.internal.RPCClientProxyHandler : Got message from RPC server Observation(id=b83c15ca-9047-4958-a106-65165e5abfbd, timestamp: 2020-01-08T10:12:45.975Z, entityType: Invocation, content=[rx.Notification@15895539 OnCompleted], deduplicationIdentity=e3f6d696-dea4-45b0-95b8-f9c0fe363a9f)
事件之间存在很大差异。
12:12:45.987 OnNext Starting- 流程开始,消耗1k个对象12:12:58.603 OnNext [B@2dceac3d]- 操作的实际结果。 因此,返回响应需要大约12.5秒。
根据Jprofiler Corda的处理时间大约为1.3秒,并发送结果。
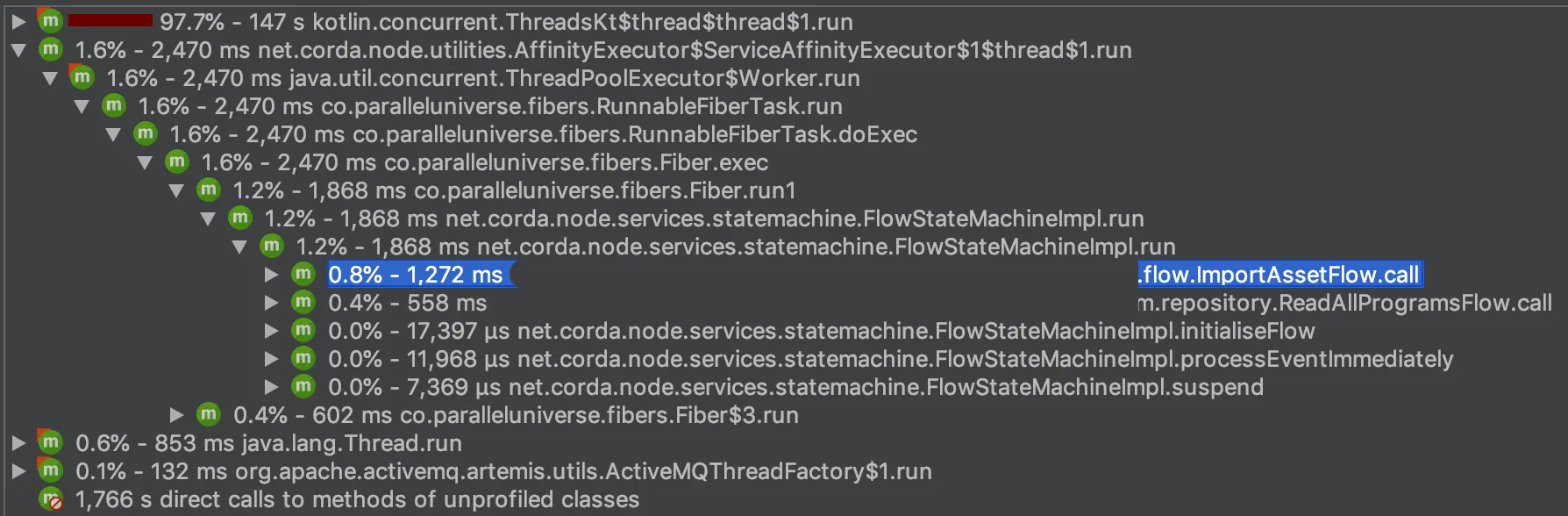
这种行为的原因可能是Artemis消息的日志记录速度较慢?
更新: 发现Corda有一个暂停/恢复机制(检查点),可以将线程状态存储到磁盘中,并在未来再次读取它并恢复此线程。 net.corda.node.services.statemachine.FlowStateMachineImpl#run 触发co.paralleluniverse.fibers.Fiber#parkAndSerialize。似乎这是其中一个时间较长的部分。
非常感谢您的帮助!