我正在使用std::nth_element来获取矢量的百分位数(大致正确的值),就像这样:
double percentile(std::vector<double> &vectorIn, double percent)
{
std::nth_element(vectorIn.begin(), vectorIn.begin() + (percent*vectorIn.size())/100, vectorIn.end());
return vectorIn[(percent*vectorIn.size())/100];
}
我注意到对于长度最多达到32个元素的向量,向量会完全排序。从33个元素开始,它就不再被排序(正如预期)。
不确定这是否重要,但该函数位于通过Matlab使用“Microsoft Windows SDK 7.1(C ++)”编译的“(Matlab-)mex c ++代码”中。
编辑:
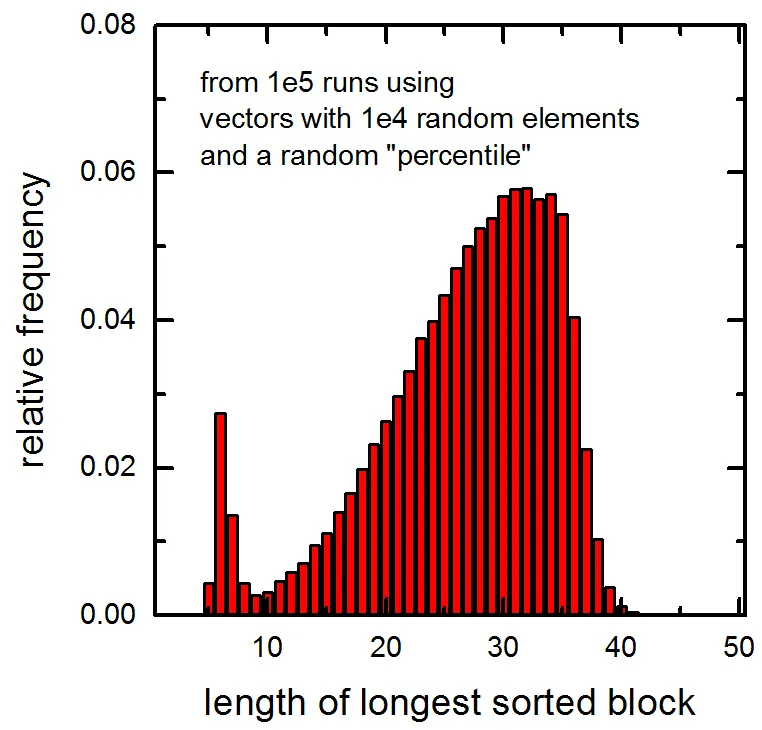
另请参见传递给函数的1e5个向量中最长排序块的长度的以下直方图(向量包含1e4个随机元素,然后计算了一个随机百分位数)。请注意非常小值处的峰值。