我正在创建一个新网站,想要通过与我的主题相关的另一个网络服务来宣传它。我想送一些礼物给那些推广我的第一个网站和粉丝页面的人。如何筛选出点赞/分享/评论我帖子最多的20个用户?
任何适合的编程语言都可以。
[编辑]
好吧...说实话,我正在寻找一种解析不属于我的粉丝页面的方法。我想送礼物给竞争对手粉丝页面上最活跃的用户,简单地贿赂他们 :)
我正在创建一个新网站,想要通过与我的主题相关的另一个网络服务来宣传它。我想送一些礼物给那些推广我的第一个网站和粉丝页面的人。如何筛选出点赞/分享/评论我帖子最多的20个用户?
任何适合的编程语言都可以。
[编辑]
好吧...说实话,我正在寻找一种解析不属于我的粉丝页面的方法。我想送礼物给竞争对手粉丝页面上最活跃的用户,简单地贿赂他们 :)
有很多方法,我将从最简单的开始...
假设涉及品牌名称或#hashtag,则可以使用搜索API进行如下操作:https://graph.facebook.com/search?q=watermelon&type=post&limit=1000 ,然后迭代数据,例如最新的1000个(limit参数),以找出所有状态中出现最多的用户(即最常出现的用户)。
如果只是一个页面,则可以访问/<page>/posts终点(例如:https://developers.facebook.com/tools/explorer?method=GET&path=cocacola%2Fposts),这将给您最新帖子的列表(它们被分页,因此您可以迭代结果),其中包括喜欢帖子和评论帖子的人的列表;然后您可以找到最常见的用户等等。
就代码而言,您可以使用任何东西,甚至可以在本地计算机上使用简单的Web服务器(例如MAMP或WAMP等)或CLI运行此代码。响应是所有JSON格式的,现代语言都能够处理这个格式。以下是我用Python编写的第一种方法的快速示例:
import json
import urllib2
from collections import Counter
def search():
req = urllib2.urlopen('https://graph.facebook.com/search?q=watermelon&type=post')
res = json.loads(req.read())
users = []
for status in res['data']:
users.append(status['from']['name'])
count = Counter(users)
print count.most_common()
if __name__ == '__main__':
search()
如果您以后想要参考它,我已将其发布在 GitHub 上:https://github.com/ahmednuaman/python-facebook-search-mode-user/blob/master/search.py
运行代码后,它会返回一个按顺序排列的用户列表,例如那些使用特定搜索标签发表了最多评论的用户。如果您希望使用第二种方法,这很容易适应。
基于Ahmed Nuaman的答案(请也点赞给他),我准备了以下代码:
用法示例:
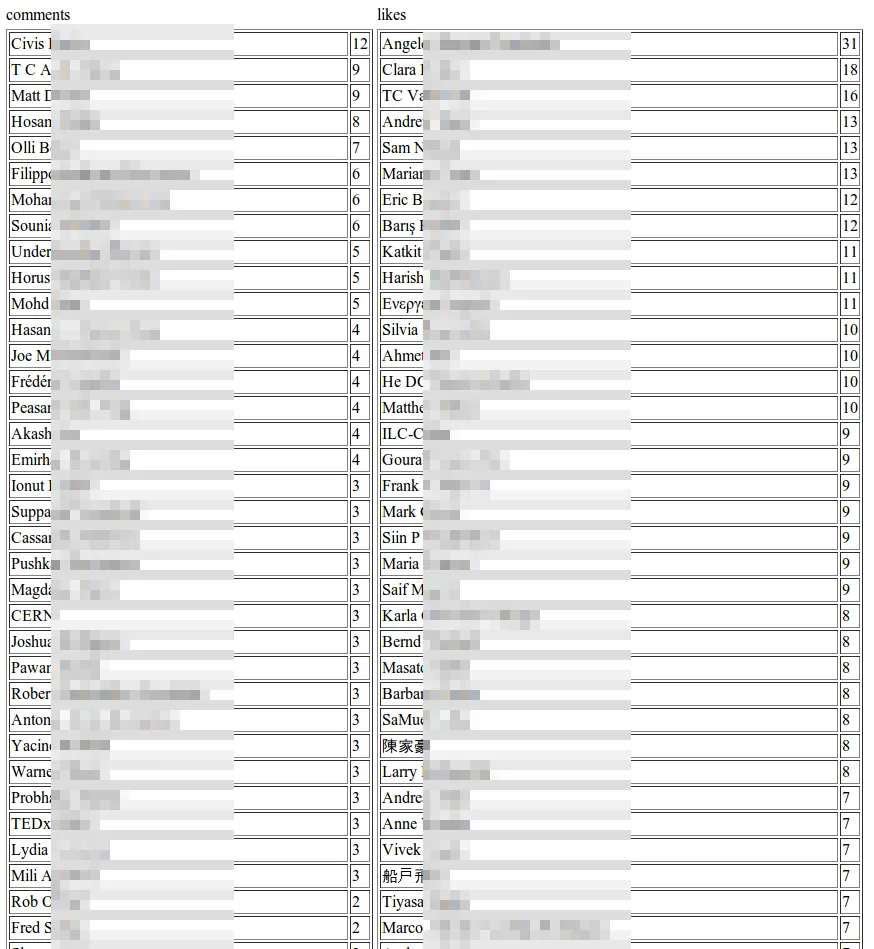
分析http://www.facebook.com/cern最活跃的Facebook用户:
$ python FacebookFanAnalyzer.py cern likes
$ python FacebookFanAnalyzer.py cern comments
$ python FacebookFanAnalyzer.py cern likes comments
注意:不支持分享和内部评论
文件:FacebookFanAnalyzer.py
# -*- coding: utf-8 -*-
import json
import urllib2
import sys
from collections import Counter
reload(sys)
sys.setdefaultencoding('utf8')
###############################################################
###############################################################
#### PLEASE PASTE HERE YOUR TOKEN, YOU CAN GENERETE IT ON:
#### https://developers.facebook.com/tools/explorer
#### GENERETE AND PASTE NEW ONE, WHEN THIS WILL STOP WORKING
token = 'AjZCBe5yhAq2zFtyNS4tdPyhAq2zFtyNS4tdPw9sMkSUgBzF4tdPw9sMkSUgBzFZCDcd6asBpPndjhAq2zFtyNS4tsBphqfZBJNzx'
attrib_limit = 100
post_limit = 100
###############################################################
###############################################################
class FacebookFanAnalyzer(object):
def __init__(self, fanpage_name, post_limit, attribs, attrib_limit):
self.fanpage_name = fanpage_name
self.post_limit = post_limit
self.attribs = attribs
self.attrib_limit = attrib_limit
self.data={}
def make_request(self, attrib):
global token
url = 'https://graph.facebook.com/' + self.fanpage_name + '/posts?limit=' + str(self.post_limit) + '&fields=' + attrib + '.limit('+str(self.attrib_limit)+')&access_token=' + token
print "Requesting '" + attrib + "' data: " + url
req = urllib2.urlopen(url)
res = json.loads(req.read())
if res.get('error'):
print res['error']
exit()
return res
def grep_data(self, attrib):
res=self.make_request(attrib)
lst=[]
for status in res['data']:
if status.get(attrib):
for person in status[attrib]['data']:
if attrib == 'likes':
lst.append(person['name'])
elif attrib == 'comments':
lst.append(person['from']['name'])
return lst
def save_as_html(self, attribs):
filename = self.fanpage_name + '.html'
f = open(filename, 'w')
f.write(u'<html><head></head><body>')
f.write(u'<table border="0"><tr>')
for attrib in attribs:
f.write(u'<td>'+attrib+'</td>')
f.write(u'</tr>')
for attrib in attribs:
f.write(u'<td valign="top"><table border="1">')
for d in self.data[attrib]:
f.write(u'<tr><td>' + unicode(d[0]) + u'</td><td>' +unicode(d[1]) + u'</td></tr>')
f.write(u'</table></td>')
f.write(u'</tr></table>')
f.write(u'</body>')
f.close()
print "Saved to " + filename
def fetch_data(self, attribs):
for attrib in attribs:
self.data[attrib]=Counter(self.grep_data(attrib)).most_common()
def main():
global post_limit
global attrib_limit
fanpage_name = sys.argv[1]
attribs = sys.argv[2:]
f = FacebookFanAnalyzer(fanpage_name, post_limit, attribs, attrib_limit)
f.fetch_data(attribs)
f.save_as_html(attribs)
if __name__ == '__main__':
main()
输出:
Requesting 'comments' data: https://graph.facebook.com/cern/posts?limit=50&fields=comments.limit(50)&access_token=AjZCBe5yhAq2zFtyNS4tdPyhAq2zFtyNS4tdPw9sMkSUgBzF4tdPw9sMkSUgBzFZCDcd6asBpPndjhAq2zFtyNS4tsBphqfZBJNzx
Requesting 'likes' data: https://graph.facebook.com/cern/posts?limit=50&fields=likes.limit(50)&access_token=AjZCBe5yhAq2zFtyNS4tdPyhAq2zFtyNS4tdPw9sMkSUgBzF4tdPw9sMkSUgBzFZCDcd6asBpPndjhAq2zFtyNS4tsBphqfZBJNzx
Saved to cern.html
/feed连接处的帖子列表,并跟踪发布和评论每个帖子的用户ID,建立经常执行此操作的用户列表。然后将这些存储在某个地方,在系统的一部分中使用存储的列表来决定要发送奖金给谁。你的问题很好,但是它非常困难...(实际上,在开始时,我脑海中有一个东西让我觉得这是不可能的。所以,我构建了一个非常不同的解决方案...)其中最好的方法之一是创建一个网络,您的观众可以在注册表单中注册,该表单需要他们的社交网络页面的官方URL,并且他们还可以选择他们没有这种类型的网络:
“您想分享我们的某个页面吗?请先在此处注册。”
因此,当他们在您的网站上时,他们可以获得他们想要分享的特定URL,但他们不知道当他们访问该特定URL时,他们正在被追踪..(每次访问特定URL时,将在数据库中跟踪IP并将访问次数 ++1 ) 在您网站的每个页面的文本区域上为他们提供动态URL以跟踪他们。或者使用脚本将跟踪查询字符串自动添加到您网站的URL中。
我认为有一个免费的软件可以建立一个联盟网络,使这变得容易!如果你的观众真的喜欢你的网站,他们会注册成为联盟会员。但是这个东西不同,联盟网络与上面段落中提到的网络相当不同。
但我认为,您也可以使用Google Analytics来完全跟踪一些没有来自动态查询字符串URL(如Digital Point)的引荐,但不是来自其他社交网络,如Facebook,因为您无法获取该类社交网络的确切引荐路径,因为查询路径。但是,您可以用它来跟踪其他网络。此外,AddThis Analytics对于非查询字符串URL非常好。
Google Analytics上的两种引荐都在标准报告的“流量来源”菜单下。
这个答案看起来有点凌乱,但有时候还是很有用的。请参阅下面的链接: