我最近参加了一次面试,被问到“编写一个程序,在10亿个数字的数组中找出最大的100个数字”。
我只能提供一种暴力解决方案,即在O(nlogn)的时间复杂度内对数组进行排序并取最后100个数字。
Arrays.sort(array);
面试官在寻求更好的时间复杂度,我尝试了几种其他的解决方案,但都无法回答他。是否有更好的时间复杂度解决方案?
我最近参加了一次面试,被问到“编写一个程序,在10亿个数字的数组中找出最大的100个数字”。
我只能提供一种暴力解决方案,即在O(nlogn)的时间复杂度内对数组进行排序并取最后100个数字。
Arrays.sort(array);
面试官在寻求更好的时间复杂度,我尝试了几种其他的解决方案,但都无法回答他。是否有更好的时间复杂度解决方案?
O(log K)。(其中K = 100,要查找的元素数量。N = 10亿,数组中的总元素数量)十亿*log2(100),这比基于比较的O(N log N)排序的十亿*log2(十亿)更好1。O(N log K),而不是O(N log N),当K与N相比非常小时,这可能非常重要。
{0,1}中随机选择的,则th(i个数字中的第k个)数字的期望值为(i-k)/i,随机变量大于此值的概率为1-[(i-k)/i] = k/i。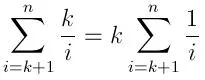
预期运行时间可以表示为:
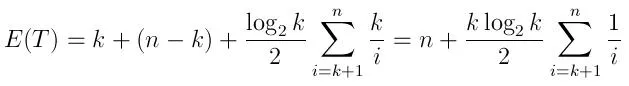
(k 次生成前 k 个元素的队列,然后进行 n-k 次比较,按照上述描述预期插入的次数,每次平均需要 log(k)/2 的时间)
需要注意的是,当 N 远大于 K 时,这个表达式更接近于 n 而不是 N log K。这在某种程度上是直观的,因为在问题的情况下,即使进行了 10,000 次迭代(相对于十亿来说很小),一个数字被插入到队列中的概率也非常小。
但我们不知道数组值是否均匀分布。 它们可能趋向于递增,在这种情况下,大多数或所有数字都将成为最大的100个数的新候选集。此算法的最坏情况是 O(N log K)。
或者如果它们趋向于递减,则大多数最大的100个数字将非常早出现,我们的最佳运行时间基本上是 O(N + K log K),当 K 远小于 N 时,它只是 O(N)。
注1:O(N)的整数排序/直方图
计数排序或基数排序都是O(N)的,但常常有更大的常数因子,使它们在实践中比比较排序更差。在某些特殊情况下,它们实际上相当快,主要适用于窄整数类型。
例如,计数排序在数字较小的情况下表现良好。16位数字只需要一个2^16计数器数组。而且,你可以在计数排序过程中构建的直方图中扫描,而不是实际扩展为排序后的数组。
在对数组进行直方图处理后,你可以快速回答任何顺序统计查询,例如前99个最大的数字,第200到100个最大的数字。32位数字会将计数散布在一个更大的数组或哈希表中,可能需要16 GiB的内存(每个2^32计数器需要4字节)。并且在真正的CPU上,可能会出现很多TLB和缓存未命中,而不像一个2^16元素的数组,L2缓存通常会命中。
同样地,基数排序在第一次遍历后只需查看顶部的桶。但是,常数因子可能仍然大于log K,具体取决于K。k是常数且相对于n而言很小。但是,人们应该始终记住这种“正常情况”。 - ffriend我意识到这个标签是“算法”,但我会提供其他选项,因为它可能也应该被标记为“面试”。
这10亿个数字的来源是什么?如果是数据库,那么“select value from table order by value desc limit 100”就可以很好地完成工作 - 可能会有方言差异。
这是一次性的还是需要重复进行?如果需要重复进行,频率如何?如果是一次性的且数据在文件中,则“cat srcfile | sort (options as needed) | head -100”将让您快速地完成您获得报酬的轻松工作。
如果需要重复进行,建议选择任何合适的方法获取初始答案并存储/缓存结果,以便您能够不断地报告前100个。
最后,还有一个考虑因素。您正在寻找入门级工作,并与极客经理或未来的同事面试吗?如果是这样,您可以放弃所有描述相对技术优缺点的方法。如果您正在寻找更高级的管理工作,那么请像管理人员一样处理,关注解决方案的开发和维护成本,并说“非常感谢”,如果面试官想要专注于计算机科学的琐事,请离开。在那里,他和您都不太可能有太多的晋升机会。
祝您下次面试好运。
我的第一反应是使用堆,但也有办法在使用QuickSelect时不必将所有的输入值都保存在内存中。
创建一个大小为200的数组,并用前200个输入值填充它。运行QuickSelect并丢弃低100个值,这样就有了100个空位。读入接下来的100个输入值并再次运行QuickSelect。继续以100个一组地处理整个输入,直到处理完全部输入。
最终你会得到前100个数。如果有N个值,你需要大约运行N/100次QuickSelect。每个Quickselect的成本大约是某个固定常数的200倍,因此总成本是2N乘以某个常数。在我看来,这看起来是关于输入规模的线性级别,而无论我在本说明中硬编码的参数大小是100还是其他的。
partial_sort相当。 - dypOrdering.greatestOf(Iterable, int)所做的。它绝对是线性时间和单遍扫描,而且是一个超级可爱的算法。我们还有一些实际的基准测试:在平均情况下,其常数因子略慢于传统的优先队列,但是这个实现对“最坏情况”输入(例如严格升序输入)更加抗过载。 - Louis Wassermanarray={...the billion numbers...}
result[100];
pivot=QuickSelect(array,billion-101);//O(N)
for(i=0;i<billion;i++)//O(N)
if(array[i]>=pivot)
result.add(array[i]);
该算法的时间复杂度为:2 X O(N) = O(N)(平均情况下的性能)
第二种选择,就像Thomas Jungblut所建议的那样:
使用堆(Heap)构建最大堆将花费O(N)的时间,然后前100个最大的数字将位于堆的顶部,你只需要从堆中取出这100个数字(100 X O(Log(N)))。
该算法的时间复杂度为:O(N) + 100 X O(Log(N)) = O(N)
O(N),但进行两次快速选择和另一个线性扫描的开销远远超出所需。 - Kevin100*O(N)(如果语法有效)= O(100*N) = O(N)(尽管100可能是变量,所以这不是严格准确的)。哦,还有快速选择的最坏情况时间复杂度为O(N^2)(糟糕)。如果数据不适合内存,你将会从磁盘加载数据两次,这比一次更糟糕(这是性能瓶颈)。 - Bernhard Barker尽管另一种快速选择的解决方案已被投票降级,但事实仍然存在:与使用大小为100的队列相比,快速选择将更快地找到解决方案。从比较的角度来看,快速选择的期望运行时间为2n + o(n)。一个非常简单的实现方式是
array = input array of length n
r = Quickselect(array,n-100)
result = array of length 100
for(i = 1 to n)
if(array[i]>r)
add array[i] to result
平均来说,这将需要 3n + o(n) 次比较。此外,使用快速选择算法能够更加高效,因为它会将数组中最大的100个元素留在右侧100个位置上。因此,实际的运行时间可以提高到2n + o(n)。
问题在于这是期望的运行时间,而不是最坏情况下的。但是通过使用一个合理的枢轴选择策略(例如,随机选择21个元素,并选择其中位数作为枢轴),比较次数可以保证以高概率不超过(2+c)n,其中c是任意小的常数。
事实上,通过使用优化的抽样策略(例如,随机抽取sqrt(n)个元素,选择第99个百分位数),可以将运行时间降低到(1+c)n + o(n),其中c是任意小的常数(假设要选择的元素数量K是o(n))。
另一方面,使用大小为100的队列将需要O(log(100)n)次比较,而100的对数近似等于6.6。
如果我们将这个问题看作是在大小为N的数组中选择前K个最大的元素,其中K=o(N),但是K和N都增长到无穷大,那么快速选择版本的运行时间将是O(N),队列版本的运行时间将是O(N log K),因此从这个角度来看,快速选择也是渐进上优越的。
在评论中提到,对于随机输入,队列解决方案将在预期的时间内运行N + K log N。当然,除非问题明确说明,否则不可能假设输入是随机的。可以使队列解决方案以随机顺序遍历数组,但这将产生额外的代价:需要调用N次随机数生成器以及重新排列整个输入数组或者分配一个新的长度为N的数组来包含随机索引。
如果问题不允许移动原始数组中的元素,并且分配内存的成本很高,因此不能复制数组,那就是另一回事了。但严格按照运行时间来说,这是最佳解决方案。
取出十亿个数中的前100个并进行排序。现在只需要遍历这十亿个数,如果源数大于前100个数中最小的数,则按顺序插入排序。最终得到的结果比集合大小为O(n)更接近。
两种选择:
(1) 堆(优先队列)
维护一个大小为100的最小堆。遍历数组。一旦元素小于堆中的第一个元素,就替换它。
InSERT ELEMENT INTO HEAP: O(log100)
compare the first element: O(1)
There are n elements in the array, so the total would be O(nlog100), which is O(n)
(2) Map-reduce模型。
这与Hadoop中的单词计数示例非常相似。 Map任务:计算每个元素的频率或出现次数。 Reduce任务:获取前K个元素。
通常,我会给招聘者两个答案。给他们喜欢的那个。当然,编写map reduce代码可能会很费力,因为您必须知道每个确切参数。练习一下也无妨。 祝你好运。
一个非常简单的解决方案是通过数组迭代100次来解决,这是O(n)复杂度。
每次取出最大的数字(并将其值更改为最小值,这样下一次迭代就不会看到它,或者通过跟踪先前答案的索引(通过跟踪索引,原始数组可以有多个相同的数字)来保持索引)。经过100次迭代,您就有了最大的100个数字。
O(1),因为没有维度增加。面试官应该问:“如何从一个长度为n的数组中找到m个最大的元素,其中n>>m?” - Bakuriu