一对多和多对一关系之间的真正区别是什么?只是反过来而已吗?
我找不到任何“易于理解”的好教程,除了这个链接:SQL for Beginners: Part 3 - Database Relationships
一对多和多对一关系之间的真正区别是什么?只是反过来而已吗?
我找不到任何“易于理解”的好教程,除了这个链接:SQL for Beginners: Part 3 - Database Relationships
是的,情况相反也一样。这取决于实体在关系的哪一侧。
例如,如果一个部门可以雇用多名员工,则部门到员工是一对多关系(1个部门雇用多名员工),而员工到部门的关系是多对一(多名员工在一个部门工作)。
更多关于关系类型的信息:
从这篇关于数据库术语的页面中:
表之间的大多数关系都是一对多。
例如:
- 一个区域可以是许多读者的栖息地。
- 一个读者可以有很多订阅。
- 一家报社可以有很多订阅。
多对一关系与一对多关系相同,但是从不同的视角看待。
- 许多读者住在同一个区域。
- 许多订阅可能属于同一个读者。
- 许多订阅都是为同一家报纸的。
id,name
1,Bill Smith
2,Jim Kenshaw
如果要将一个订单与一个客户关联,许多SQL实现会在订单表中添加一列来存储关联的客户的id(在此模式中为customer_id):
id,date,amount,customer_id
10,20160620,12.34,1
11,20160620,7.58,1
12,20160621,158.01,2
customer_id id列,我们会发现Bill Smith(客户编号#1)有两个与之关联的订单:一个金额为$12.34,另一个金额为$7.58。而Jim Kenshaw(客户编号#2)只有一笔金额为$158.01的订单。Customer没有描述与Order关系的额外列。事实上,Customer可能还与ShippingAddress和SalesCall表存在一对多的关系,但Customer表中没有添加额外的列。但是,也有可能存在另一个描述Customer和Order关系的表,因此不需要向Order表添加其他字段。可以有一个名为Customer_Order的表,其中包含Customer和Order的键。
customer_id,order_id
1,10
1,11
2,12

在SQL中,只有一种类型的关系,被称为引用。 (您的前端可能会执行有用或令人困惑的操作 [例如在某些答案中],但这是另一回事。)
一个表格中的外键(指向其他表格中的主键)
被称为参考
在SQL术语中,Bar引用Foo
而不是反过来
CREATE TABLE Foo (
Foo CHAR(10) NOT NULL, -- primary key
Name CHAR(30) NOT NULL
CONSTRAINT PK -- constraint name
PRIMARY KEY (Foo) -- pk
)
CREATE TABLE Bar (
Bar CHAR(10) NOT NULL, -- primary key
Foo CHAR(10) NOT NULL, -- foreign key to Foo
Name CHAR(30) NOT NULL
CONSTRAINT PK -- constraint name
PRIMARY KEY (Bar), -- pk
CONSTRAINT Foo_HasMany_Bars -- constraint name
FOREIGN KEY (Foo) -- fk in (this) referencing table
REFERENCES Foo(Foo) -- pk in referenced table
)
由于Foo.Foo是主键,它是唯一的,对于任何给定的Foo值,只有一行。
由于Bar.Foo是一个参考、外键,并且没有唯一索引,因此对于任何给定的Foo值,可能有多个行。
因此关系Foo::Bar是一对多的。
现在你可以从另一个角度观察这种关系,Bar::Foo是多对一的。
Bar行,它只引用了一个Foo行。在SQL中,这就是我们所拥有的。这就是所有必需的。
一对多和多对一关系之间的真正区别是什么?
只有一个关系,因此不存在区别。从一个“端点”或另一个“端点”感知(观察),或者倒过来读,都不会改变这种关系。
基数首先在数据模型中声明,这意味着逻辑和物理(意图),然后在实现中(实现的意图)。
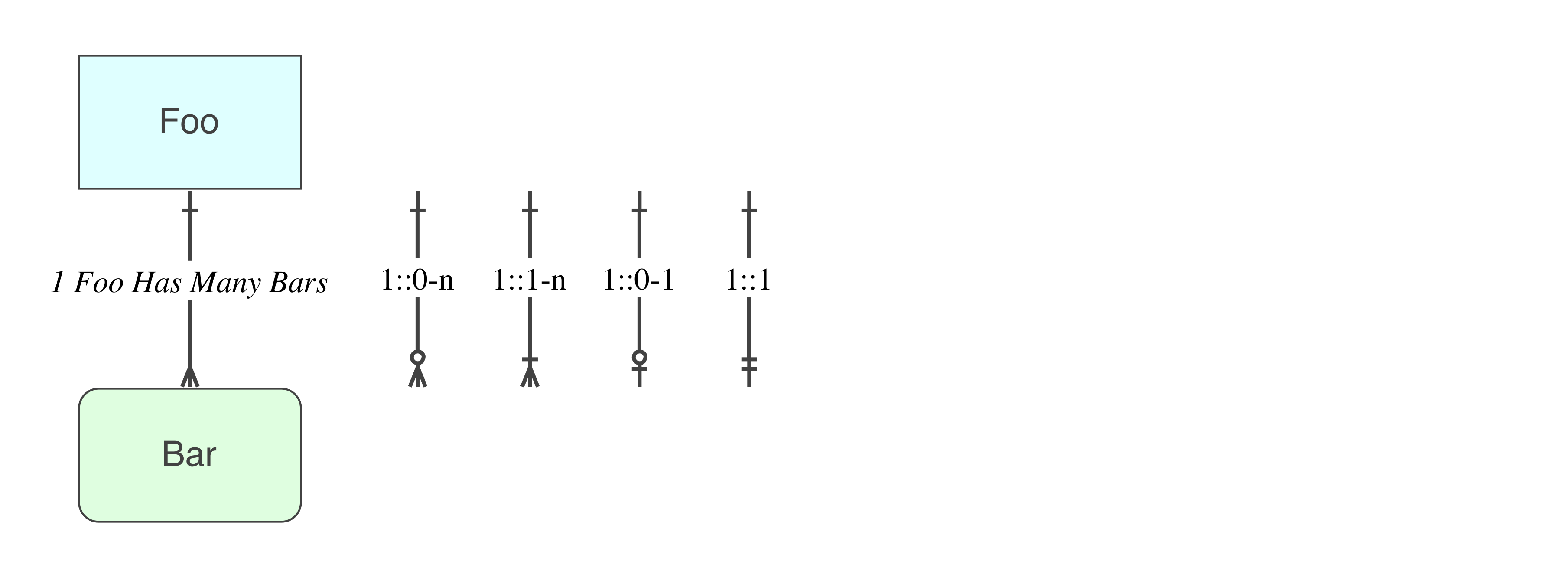
一对零或多个
在SQL中,这就是所需的(如上所述)。
一对一对多
您需要一个事务来强制执行引用表中的“一”。
一对零或一
您需要在Bar中:
CONSTRAINT AK -- constraint name
UNIQUE (Foo) -- unique column, which makes it an Alternate Key
一对一
你需要一个事务来强制Referencing表中的一对一。
在物理层面上不存在这样的东西(请注意,SQL中只有一种类型的关系)。
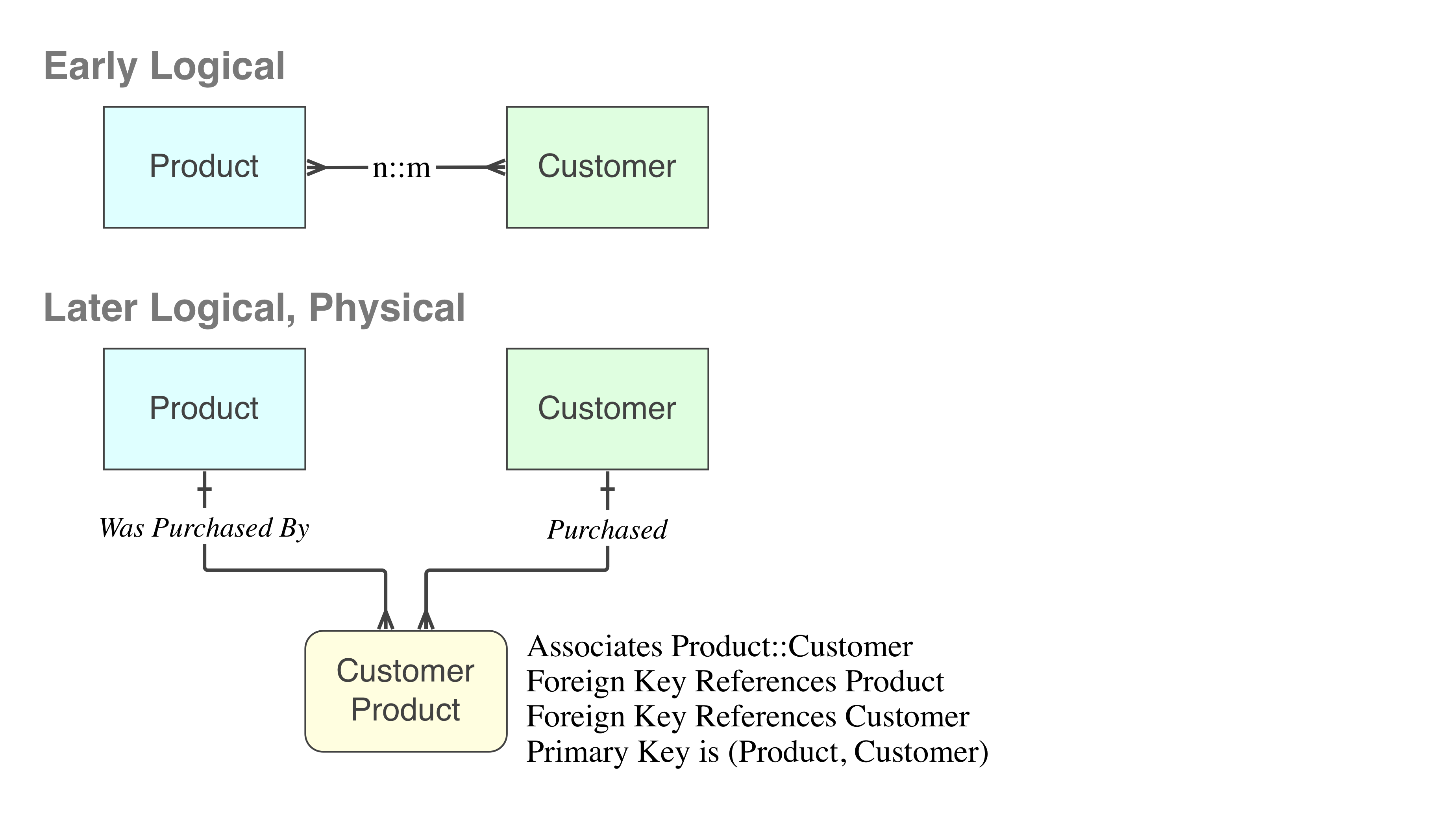
在建模练习的早期逻辑层面上,画这样的关系是方便的。在模型接近实现之前,最好使用只能存在的东西来升华它。这样的关系通过在物理[DDL]层面上实现一个联结表来解决。
没有区别,只是语言和个人偏好的问题,关系的表述方式不同而已。
你第一个问题的答案是:两者相似。
你第二个问题的答案是:一对多--> 一个男人(男人表)可以有多个妻子(女人表),多对一--> 多个女人已经嫁给了一个男人。
现在,如果你想将这种关系与 MAN 和 WOMEN 两个表关联起来,那么 MAN 表的一行可能与 WOMEN 表中的多行有多个关系。希望这样清楚明白。
实际上没有什么区别。只需根据您看待问题的方式使用最合理的关系,就像Devendra所示。
一对多和多对一关系是指同一逻辑关系,例如一个所有者可能拥有多个房屋,但一个房屋只能有一个所有者。
因此,在这个例子中,所有者是“一”,而房屋是“多”。 每个房屋都有一个owner_id(例如外键)作为额外的列。
这两者之间实现的区别在于哪个表定义了关系。 在一对多中,所有者是定义关系的地方。例如,owner1.homes列出了所有带有owner1的owner_id的房屋。 在多对一中,房屋是定义关系的地方。例如,home1.owner列出了owner1的owner_id。
我实际上不知道在什么情况下会实现多对一的安排,因为它似乎有点多余,因为您已经知道owner_id。也许与删除和更改的清洁度有关。